上下文工程:会话,记忆
作者:Kimberly Milam 和 Antonio Gulli
致谢
内容贡献者
Kaitlin Ardiff
Shangjie Chen
Yanfei Chen
Derek Egan
Hangfei Lin
Ivan Nardini
Anant Nawalgia
Kanchana Patlolla
Huang Xia
Jun Yan
Bo Yang
Michael Zimmermann
策展人和编辑
Anant Nawalgia
Kanchana Patlolla
设计师
Michael Lanning

目录
1. 介绍 .......................................... 6
2. 上下文工程 .......................................... 7
3. 会话 .......................................... 12
3.1 框架和模型之间的差异 .......................................... 13
3.2 多智能体系统的会话 .......................................... 15
多智能体框架之间的互操作性 .......................................... 19
3.3 会话的生产考虑事项 .......................................... 20
3.4 管理长上下文对话:权衡与优化 .......................................... 22
4. 记忆 .......................................... 27
4.1 记忆类型 .......................................... 34
信息类型 .......................................... 35
组织模式 .......................................... 35
存储架构 .......................................... 36
创建机制 .......................................... 37
记忆范围 .......................................... 38
多模态记忆 .......................................... 39
4.2 记忆生成:提取与巩固 .......................................... 41
深入探讨:记忆提取 .......................................... 44
深入探讨:记忆巩固 .......................................... 47
记忆溯源 .......................................... 49
记忆管理期间对记忆谱系的考量 .......................................... 50
推理期间对记忆谱系的考量 .......................................... 52
触发记忆生成 .......................................... 52
记忆作为工具 .......................................... 53
背景操作与阻塞操作 .......................................... 56
4.3 记忆检索 .......................................... 56
检索时机 .......................................... 58
4.4 使用记忆进行推理 .......................................... 61
系统指令中的记忆 .......................................... 61
对话历史中的记忆 .......................................... 63
4.4 程序性记忆 .......................................... 64
4.5 测试与评估 .......................................... 65
4.6 记忆的生产考虑事项 .......................................... 67
隐私和安全风险 .......................................... 69
结论 .......................................... 70
参考 .......................................... 71
状态化和个性化AI始于上下文工程。
1. 介绍
本白皮书探讨了会话和记忆在构建状态化、智能大语言模型(LLM)代理中的关键作用,以帮助开发者创建更强大、个性化且持久的AI体验。为了使大语言模型能够记住、学习和个性化交互,开发者必须在上下文窗口内动态组装和管理信息——这一过程被称为上下文工程。 以下核心概念在白皮书中有总结:
- 上下文工程:动态组装和管理LLM上下文窗口内信息的过程,以实现状态化、智能代理。
- 会话:与代理整个对话的容器,包含对话的时序历史和代理的工作记忆。
- 记忆:长期持久化的机制,通过跨多个会话捕获和巩固关键信息,为LLM代理提供持续和个性化的体验。
2. 上下文工程
LLM本质上是无状态的。除了其训练数据外,其推理和意识局限于单个API调用中的“上下文窗口”内的信息。这提出了一个基本问题,因为AI代理必须配备操作指令,以识别可以执行的操作、推理所需的证据和事实数据,以及定义当前任务的即时对话信息。为了构建能够记住、学习和个性化交互的状态化、智能代理,开发者必须为每次对话的每个回合构建这种上下文。这种为LLM动态组装和管理信息的过程被称为上下文工程。
上下文工程代表了从传统提示工程到的一种演变。提示工程侧重于制作最优的、通常是静态的系统指令。相反,上下文工程关注整个负载,根据用户、对话历史和外部数据动态构建一个状态感知的提示。它涉及战略性地选择、总结和注入不同类型的信息,以最大化相关性同时最小化噪声。外部系统,如RAG数据库、会话存储和记忆管理器,管理着大部分上下文。代理框架必须协调这些系统,以检索和组装上下文到最终的提示。
将上下文工程视为为智能体准备 mise en place 的关键步骤——在这一步骤中,厨师在烹饪前收集和准备所有食材。如果只给厨师一份食谱(提示),他们可能会用随机找到的食材做出一份不错的餐点。然而,如果首先确保他们拥有所有正确、高质量的食材,专业的工具和清晰的呈现风格,他们就能可靠地制作出出色、定制的成果。上下文工程的目标是确保模型拥有完成任务所需的最相关信息的量,既不多也不少。
上下文工程管理着复杂负载的组装,这可能包括各种组件:
- 指导推理的上下文定义了智能体的基本推理模式和可用动作,决定了其行为:
- 系统指令:定义智能体角色、能力和约束的高级指令。
- 工具定义:智能体用于与外界交互的 API 或函数的架构。
-
少样本示例:通过情境学习引导模型推理过程的精选示例。
-
证据与事实数据是智能体推理的实质性数据,包括现有知识和为特定任务动态检索的信息;它作为智能体响应的“证据”:
-
长期记忆:用户或主题的持久知识,跨越多个会话收集。
- 外部知识:从数据库或文档中检索的信息,通常使用检索增强生成(RAG)技术。
- 工具输出:工具返回的数据或结果。
- 子智能体输出:被委派特定子任务的专门智能体返回的结论或结果。
- 物料:与用户或会话相关的非文本数据(例如,文件、图像)。
- 立即的对话信息使智能体立足于当前交互,定义了立即的任务:
- 对话历史:当前交互的逐轮记录。
- 状态/草稿:智能体用于其即时推理过程的临时、进行中的信息或计算。
- 用户的提示:需要立即解决的问题。
上下文动态构建至关重要。例如,记忆不是静态的;它们必须根据用户与智能体交互或新数据摄入的情况进行选择性检索和更新。此外,有效的推理通常依赖于情境学习(LLM 通过提示中的演示学习如何执行任务的流程)。当智能体使用与当前任务相关的少样本示例而不是依赖硬编码的示例时,情境学习可以更有效。同样,外部知识是通过 RAG 工具根据用户的即时查询检索的。
构建具有上下文感知能力的智能体最关键的挑战之一是管理不断增长的对话历史。理论上,具有大上下文窗口的模型可以处理大量的转录文本;在实践中,随着上下文的增长,成本和延迟会增加。此外,模型可能会遭受“上下文老化”的现象,即随着上下文的增长,它们关注关键信息的能力减弱。上下文工程通过采用策略直接解决这个问题,例如摘要、选择性修剪或其他压缩技术,以在管理整体令牌计数的同时保留关键信息,最终导致更稳健和个性化的 AI 体验。
这种实践表现为智能体操作循环中对话每轮的持续循环:
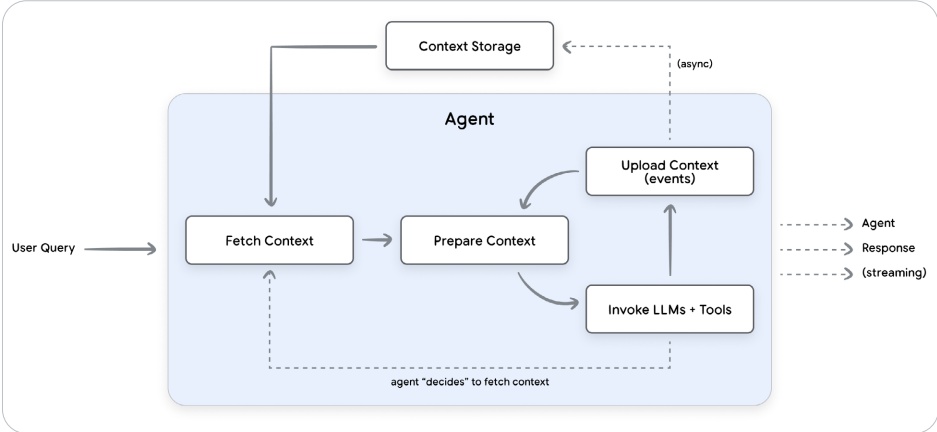
- 获取上下文:代理首先检索上下文,例如用户记忆、RAG文档和最近的对话事件。对于动态上下文检索,代理将使用用户查询和其他元数据来识别需要检索的信息。
- 准备上下文:代理框架动态构建LLM调用的完整提示。尽管单个API调用可能是异步的,但准备上下文是一个阻塞的、“热点”过程。代理在上下文准备就绪之前无法继续。
- 调用LLM和工具:代理迭代调用LLM和任何必要的工具,直到生成针对用户的最终响应。工具和模型输出将被附加到上下文中。
- 上传上下文:在回合中收集的新信息将被上传到持久存储。这通常是一个“后台”过程,允许代理在记忆巩固或其他异步后处理过程中完成执行。
在这个生命周期中,有两个基本组件:会话和记忆。会话管理单个对话的逐回合状态。相比之下,记忆提供了长期持久化的机制,跨多个会话捕获和整合关键信息。
您可以想象会话为特定项目使用的工坊或办公桌。在您工作的时候,它上面覆盖着所有必要的工具、笔记和参考资料。所有东西都是立即可访问的,但也是临时的,并且针对手头的任务。一旦项目完成,您不会把整个杂乱的办公桌直接塞进储藏室。相反,您开始创建记忆的过程,这就像一个有组织的文件柜。您会审查办公桌上的材料,丢弃草稿和冗余的笔记,并将仅有的最关键、最终确定的文件归档到标签文件夹中。这确保了文件柜始终保持干净、可靠和高效的真相来源,而不会被工坊的短暂混乱所 cluttered。这个类比直接反映了有效代理的运作方式:会话作为单个对话的临时工坊,而代理的记忆则是精心组织的文件柜,允许它在未来的交互中回忆关键信息。
在概述上下文工程的基础上,我们现在可以探索两个核心组件:会话和记忆,从会话开始。
3. 会话
上下文工程的基础元素是会话,它封装了单个连续对话的即时对话历史和工作记忆。每个会话都是一个自包含的记录,与特定用户相关联。会话允许代理在单个对话的范围内维持上下文并提供连贯的响应。用户可以有多个会话,但每个会话都作为一个特定交互的独立、断开的日志运行。每个会话包含两个关键组件:按时间顺序的历史记录(事件)和代理的工作记忆(状态)。
事件是对话的构建块。常见的事件类型包括:用户输入(用户的消息(文本、音频、图像等))、代理响应(代理对用户的回复)、工具调用(代理决定使用外部工具或API)或工具输出(工具调用的数据返回,代理使用这些数据继续其推理)。
除了聊天历史记录之外,会话通常还包括一个状态——一个结构化的“工作记忆”或便笺簿。它持有与当前对话相关的临时、结构化数据,例如购物车中的物品。
随着对话的进行,代理将向会话中追加更多事件。此外,它可能根据代理中的逻辑修改状态。
事件的结构与传递给 Gemini API 的内容对象列表类似,其中每个具有角色和部分的条目代表对话中的一轮——或一个事件。
contents = [
{
"role": "user",
"parts": [
{
"text": "What is the capital of France?"
}
],
{
"role": "model",
"parts": [
{
"text": "The capital of France is Paris."
}
]
}
}
]
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=contents
)
生产型代理的执行环境通常是无状态的,这意味着在请求完成后不会保留任何信息。因此,其对话历史必须保存到持久存储中,以保持连续的用户体验。虽然记忆存储适合开发,但生产应用应利用强大的数据库来可靠地存储和管理会话。例如,您可以将对话历史存储在像 Agent Engine Sessions $ ^{3} $ 这样的托管解决方案中。
3.1 框架和模型之间的差异
虽然核心思想相似,但不同的代理框架以不同的方式实现会话、事件和状态。代理框架负责维护 LLM 的对话历史和状态,使用此上下文构建 LLM 请求,并解析和存储 LLM 的响应。
代理框架充当您代码和 LLM 之间的通用翻译器。虽然您作为开发者,在每次对话轮次中与框架的一致、内部数据结构工作,但框架负责处理将那些结构转换为 LLM 所需的精确格式的关键任务。这种抽象非常强大,因为它将代理逻辑与您使用的特定 LLM 解耦,防止了供应商锁定。

最终目标是生成一个LLM能够理解的“请求”。对于谷歌的Gemini模型,这表现为一个$$ 内容 $$列表。每个内容对象都是一个类似于字典的简单结构,包含两个键:role(定义说话者是谁,“用户”或“模型”)和parts(定义消息的实际内容,如文本、图像、工具调用等)。 框架会自动处理将数据从其内部对象(例如ADK事件)映射到内容对象中相应的role和parts,然后再进行API调用。本质上,框架为开发者提供了一个稳定、内部的API,同时在幕后管理不同LLM的复杂且多样化的外部API。
ADK使用一个显式的会话对象,其中包含一个事件对象列表和一个独立的状态对象。会话就像一个文件柜,一个文件夹用于存放对话历史(事件),另一个用于存放工作记忆(状态)。 LangGraph没有正式的“会话”对象。相反,状态就是会话。这个包罗万象的状态对象包含了对话历史(作为消息对象的列表)以及所有其他工作数据。与传统会话的只读日志不同,LangGraph的状态是可变的。它可以被转换,并且像历史压缩这样的策略可以改变记录。这对于管理长对话和令牌限制非常有用。
3.2 多代理系统的会话
在多代理系统中,多个代理协同工作。每个代理专注于一个较小、更专业的任务。为了这些代理能够有效地协同工作,它们必须共享信息。如图所示,系统的架构定义了它们用来共享信息的通信模式。这个架构的一个核心组件是系统如何处理会话历史——所有交互的持久日志。
| Single Agent | Network | Supervisor |
 |  |  |
| Supervisor (as tools) | Hierarchical | Custom |
 |  |  |
在探讨管理此类历史记录的架构模式之前,区分它与发送给大语言模型(LLM)的上下文至关重要。将会话历史记录想象为整个对话的永久、未经删减的记录。另一方面,上下文则是精心构建的信息负载,用于单次交互发送给LLM。智能体可能通过仅从历史记录中选择相关摘录或添加特殊格式,如引导前言,来引导模型的响应。本节重点讨论在智能体之间传递的信息,而不是发送给LLM的上下文。
智能体框架使用两种主要方法之一来处理多智能体系统的会话历史记录:共享、统一的历史记录,其中所有智能体都向单个日志贡献,或者分离、个体的历史记录,其中每个智能体维护自己的视角 $ ^{4} $ 。这两种模式之间的选择取决于任务的性质以及智能体之间期望的协作风格。
对于共享、统一的历史记录模型,系统中的所有智能体都从同一个、单一的对话历史记录中读取并写入所有事件。每个智能体的消息、工具调用和观察都按时间顺序附加到一个中央日志中。这种方法最适合紧密耦合、需要单一真相来源的协作任务,例如多步骤问题解决过程,其中一个智能体的输出是下一个智能体的直接输入。即使有共享的历史记录,子智能体也可能在将其传递给LLM之前处理日志。例如,它可以筛选出相关事件的子集或添加标签以标识哪个智能体生成了每个事件。
如果您使用ADK的LLM驱动委托将任务转交给子智能体,所有子智能体的中间事件都将写入与根智能体相同的会话中 $ ^{5} $ :
from google.adk.agents import LlmAgent
# The sub-agent has access to Session and writes events to it.
sub_agent_1 = LlmAgent(...)
# Optionally, the sub-agent can save the final response text (or structured output) to the specified state key.
sub_agent_2 = LlmAgent(
...
output_key="..."
)
Continues next page...
上下文工程是人工智能和机器学习领域中的一个关键概念,它涉及到如何有效地管理和利用数据上下文来提高模型的表现和效率。以下是对会话和记忆在上下文工程中的应用的探讨:
会话
会话(Session)是指用户与系统之间的一系列交互。在人工智能系统中,会话管理是确保用户体验连贯性和个性化的关键。以下是一些关于会话在上下文工程中的应用点:
- 多轮对话:在多轮对话中,系统需要记住之前的交互内容,以便在后续的对话中提供更加相关和个性化的回答。
- 上下文保持:通过会话管理,系统能够保持对话的上下文,避免重复提问或提供不相关的内容。
- 用户意图识别:会话历史可以帮助模型更好地理解用户的意图,从而提供更加精准的服务。
记忆
记忆(Memory)在上下文工程中扮演着至关重要的角色。以下是一些关于记忆在上下文工程中的应用:
- 长期记忆:长期记忆用于存储用户的历史交互数据,这些数据可以帮助模型更好地理解用户的行为模式和偏好。
- 短期记忆:短期记忆用于存储当前会话中的信息,确保模型能够根据最新的交互内容做出响应。
- 记忆优化:通过优化记忆结构,可以提高模型的性能,减少冗余信息,提高处理速度。
在上下文工程中,会话和记忆的应用对于提升人工智能系统的智能性和用户体验至关重要。通过有效地管理和利用这些上下文信息,我们可以构建更加智能、个性化的AI系统。
# Parent agent.
root_agent = LlmAgent(
...
sub_agents=[sub_agent_1, sub_agent_2])
在独立、个体历史模型中,每个代理维护自己的私有对话历史,并像黑盒一样对其他代理保密。所有内部过程——如中间思想、工具使用和推理步骤——都保留在代理的私有日志中,对他人不可见。通信仅通过显式消息进行,代理分享其最终输出,而不是其过程。
这种交互通常通过实现“代理作为工具”或使用“代理到代理”(A2A)协议来实现。在“代理作为工具”中,一个代理将另一个代理调用,就像调用一个标准工具一样,传递输入并接收一个最终的自包含输出 $ ^{6} $ 。在“代理到代理”(A2A)协议中,代理使用结构化协议进行直接消息传递 $ ^{7} $ 。
我们将在下一节中更详细地探讨 A2A 协议。
跨多个代理框架的互操作性
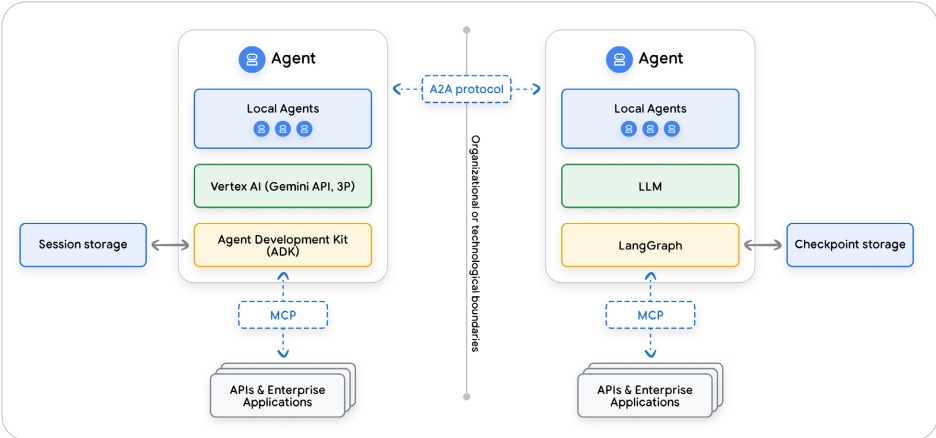
图4:使用不同框架的多个Agent之间的A2A通信
框架使用内部数据表示引入了多智能体系统的一个关键架构权衡:将智能体从大语言模型(LLM)解耦的抽象本身也将其隔离了使用其他智能体框架的智能体。这种隔离在持久化层得到巩固。会话的存储模型通常将数据库模式直接耦合到框架的内部对象,创建了一个刚性、相对不可移植的对话记录。因此,使用LangGraph构建的智能体无法原生地解释基于ADK的智能体持久化的特定会话和事件对象,使得无缝任务移交变得不可能。
一种用于协调这些隔离智能体之间协作的正在出现的架构模式是智能体到智能体(A2A)通信 $ ^{8} $ 。虽然这种模式使智能体能够交换消息,但它未能解决共享丰富、上下文状态的核心问题。每个智能体的对话历史都编码在其框架的内部模式中。因此,任何包含会话事件的A2A消息都需要一个翻译层才能变得有用。
一种更健壮的架构模式,用于实现互操作性,涉及将共享知识抽象为框架无关的数据层,例如记忆。与保留原始、框架特定对象(如事件和消息)的会话存储不同,记忆层旨在存储处理过的、规范化的信息。关键信息——如摘要、提取的实体和事实——从对话中提取,通常以字符串或字典的形式存储。记忆层的数据结构不耦合到任何单个框架的内部数据表示,这使得它可以作为一个通用、公共的数据层。这种模式允许异构智能体通过共享一个共同的认知资源来实现真正的协作智能,而无需定制翻译器。
3.3 会话的生产考虑因素
当将智能体迁移到生产环境时,其会话管理系统必须从简单的日志发展到健壮的企业级服务。关键考虑因素分为三个关键领域:安全和隐私、数据完整性和性能。像智能体引擎会话这样的托管会话存储专门设计来满足这些生产需求。
安全和隐私
保护会话中包含的敏感信息是一个不可协商的要求。严格的隔离是最重要的安全原则。会话属于单个用户,系统必须强制执行严格的隔离,以确保一个用户永远无法访问另一个用户的会话数据(例如,通过ACLs)。对会话存储的每个请求都必须对会话的所有者进行身份验证和授权。
处理个人身份信息(PII)的最佳实践是在会话数据写入存储之前对其进行编辑。这是一项基本的安全措施,可以极大地降低潜在数据泄露的风险和“爆炸半径”。通过确保敏感数据从未使用像Model Armor $ ^{9} $ 这样的工具持久化,您可以简化符合GDPR和CCPA等隐私法规的合规性,并建立用户信任。
数据完整性和生命周期管理
生产系统需要明确规则来定义会话数据如何随时间存储和维护。会话不应永远存在。您可以实施生存时间(TTL)策略来自动删除非活动会话,以管理存储成本并减少数据管理开销。这需要一个明确的数据保留策略,以定义会话在存档或永久删除之前应保留多长时间。
此外,系统必须保证操作以确定性的顺序附加到会话历史中。维护事件的正确时间顺序对于对话日志的完整性至关重要。
性能和可扩展性
会话数据是每个用户交互的“热点路径”,因此其性能是一个主要关注点。读取和写入会话历史必须非常快,以确保响应式用户体验。Agent 运行时通常是无状态的,因此在每个回合的开始,整个会话历史都会从中央数据库中检索,从而产生网络传输延迟。
为了减轻延迟,减少传输的数据量至关重要。一个关键的优化是在将会话历史发送到 Agent 之前对其进行过滤或压缩。例如,您可以移除对于当前对话状态不再需要的旧、不相关的函数调用输出。下一节详细介绍了几种压缩历史记录的策略,以有效地管理长上下文对话。
3.4 管理长上下文对话:权衡和优化
在简单的架构中,会话是用户与 Agent 之间对话的不可变日志。然而,随着对话的扩展,对话的标记使用量增加。现代大语言模型可以处理长上下文,但存在限制,尤其是在对延迟敏感的应用中[10]: 1. 上下文窗口限制:每个大语言模型一次可以处理的最大文本量(上下文窗口)是有限的。如果对话历史超过了这个限制,API 调用将失败。 2. API 成本($):大多数大语言模型提供商根据您发送和接收的标记数量收费。较短的会话历史意味着更少的标记和每回合更低的成本。 3. 延迟(速度):向模型发送更多文本需要更长的时间来处理,这会导致用户响应时间变慢。压缩可以保持 Agent 的快速响应感。 4. 质量:随着标记数量的增加,性能可能会变差,因为上下文中会有额外的噪声和自回归错误。
管理与 Agent 的长对话可以比作一个精明的旅行者为长途旅行打包行李。行李箱代表 Agent 的有限上下文窗口,而衣服和物品则是对话中的信息片段。如果你试图把所有东西都塞进去,行李箱就会变得过重且杂乱无章,难以快速找到所需的东西——就像过载的上下文窗口会增加处理成本并减慢响应时间一样。另一方面,如果你打包得太少,你可能会遗漏像护照或保暖外套这样的重要物品,从而影响整个旅程——就像 Agent 可能会丢失关键上下文,导致无关或不正确的回答。旅行者和 Agent 都在类似的约束下运作:成功不在于你能携带多少,而在于只携带你需要的东西。
压缩策略缩短长对话历史,将对话压缩到模型上下文窗口内,减少 API 成本和延迟。随着对话的变长,每个回合发送给模型的会话历史可能会变得过大。压缩策略通过智能地裁剪历史记录,同时尝试保留最重要的上下文来解决这个问题。
那么,你如何知道在不会丢失有价值信息的情况下,应该从会话中丢弃哪些内容?策略范围从简单的截断到复杂的压缩: - 保持最后 N 个回合:这是最简单的策略。Agent 只保留最近 N 个回合的对话(“滑动窗口”),并丢弃所有更早的内容。 - 基于Token的截断:在将历史信息发送给模型之前,Agent会统计消息中的Token数量,从最近的开始,向后工作。它会尽可能多地包含消息,但不超过预定义的Token限制(例如,4000个Token)。所有更早的信息都将被简单地截断。 - 递归摘要:对话中的较老部分将被AI生成的摘要所替代。随着对话的增长,Agent会定期使用另一个LLM调用来总结最旧的消息。这个摘要随后被用作历史信息的浓缩形式,通常作为较新、原文消息的前缀。 例如,您可以通过使用ADK应用内建的插件来限制发送给模型的上下文,以保留最后的N个回合与ADK的交互。这不会修改存储在您的会话存储中的历史事件:
from google.adk.apps import App
from google.adk.plugins.context_filter_plugin import ContextFilterPlugin
app = App(
name='hello_world_app',
root_agent=agent,
plugins=[
# Keep the last 10 turns and the most recent user query.
ContextFilterPlugin(num_invocations_to_keep=10),
],
)
鉴于复杂的压缩策略旨在降低成本和延迟,异步在后台执行昂贵的操作(如递归摘要)并持久化结果至关重要。“在后台”确保客户端不会被等待,而“持久化”确保昂贵的计算不会被过度重复。通常,代理的记忆管理器负责生成和持久化这些递归摘要。代理还必须记录哪些事件包含在压缩摘要中;这防止了原始、更冗长的事件被无谓地发送到 LLM。 此外,代理必须决定何时进行压缩。触发机制通常分为几个不同的类别: - 基于计数触发器(例如,令牌大小或轮数阈值):当对话超过某个预定义的阈值时,对话将被压缩。这种方法通常“足够好”,用于管理上下文长度。 - 基于时间触发器:压缩不是由对话的大小触发的,而是由缺乏活动触发的。如果用户停止交互一段时间(例如,15或30分钟),系统可以在后台运行压缩作业。 - 基于事件触发器(例如,语义/任务完成):代理在检测到特定任务、子目标或对话主题已结束时决定触发压缩。 例如,您可以使用 ADK 的 EventsCompactionConfig 在配置的轮数后触发基于 LLM 的摘要:
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
app = App(
name='hello_world_app',
root_agent=agent,
events_compaction_config=EventsCompactionConfig(
compaction_interval=5,
overlap_size=1,
)
)
记忆生成是从冗长和嘈杂的数据源中提取持久知识的广泛能力。在本节中,我们介绍了一个从对话历史中提取信息的主要示例:会话压缩。压缩提炼了整个对话的逐字记录,提取了关键事实和摘要,同时丢弃了对话填充内容。 在压缩的基础上,下一节将更广泛地探讨记忆生成和管理。我们将讨论创建、存储和检索记忆的多种方式,以构建代理的长期知识。
3. 记忆
记忆和会话之间存在着深刻的共生关系:会话是生成记忆的主要数据源,而记忆是管理会话大小的一种关键策略。记忆是从对话或数据源中提取的有意义信息的快照。它是一个简化的表示,保留了重要的上下文,使其对未来交互有用。通常,记忆会在会话之间持久化,以提供连续和个性化的体验。
作为一个专业且解耦的服务,“记忆管理器”为多代理互操作性提供了基础。记忆管理器通常使用框架无关的数据结构,如简单的字符串和字典。这允许基于不同框架构建的代理连接到单个记忆存储,从而创建一个共享的知识库,任何连接的代理都可以利用。
注意:某些框架可能也将会话或逐字对话称为“短期记忆”。对于本白皮书,记忆被定义为提取的信息,而不是逐轮对话的原始对话。
存储和检索记忆对于构建复杂和智能的智能体至关重要。一个强大的记忆系统通过解锁几个关键能力,将一个基本的聊天机器人转变为真正的智能体:
- 个性化:最常见的使用案例是记住用户偏好、事实和过去的互动,以定制未来的响应。例如,记住用户的喜爱运动队或他们偏好的飞机座位,可以创造更有帮助和个性化的体验。
- 上下文窗口管理:随着对话的变长,完整的历史可能会超出大语言模型(LLM)的上下文窗口。记忆系统可以通过创建摘要或提取关键事实来压缩历史,从而在不发送数千个令牌的每一轮中保留上下文。这减少了成本和延迟。
- 数据挖掘和洞察:通过以聚合、保护隐私的方式分析许多用户存储的记忆,你可以从噪声中提取洞察。例如,一个零售聊天机器人可能会发现许多用户都在询问特定产品的退货政策,从而标记出一个潜在问题。
- 智能体自我改进和适应:智能体通过创建关于自身性能的程序性记忆来从之前的运行中学习——记录哪些策略、工具或推理路径导致了成功的成果。这使得智能体能够构建一个有效的解决方案手册,允许其随着时间的推移适应和改进其问题解决能力。
在AI系统中创建、存储和利用记忆是一个协作过程。堆栈中的每个组件——从终端用户到开发者的代码——都有其独特的角色要扮演。
-
用户:提供记忆的原始数据源。在某些系统中,用户可以直接提供记忆(例如,通过表单)。
-
智能体(开发者逻辑):配置如何决定记住什么和何时记住,协调对记忆管理器的调用。在简单的架构中,开发者可以实施逻辑,使得记忆总是被检索和总是被触发生成。在更高级的架构中,开发者可能会实现记忆作为工具,其中智能体(通过LLM)决定何时检索或生成记忆。
-
智能体框架(例如,ADK、LangGraph):提供记忆交互的结构和工具。框架充当管道。它定义了开发者的逻辑如何访问对话历史并交互记忆管理器,但它本身不管理长期存储。它还定义了如何将检索到的记忆填充到上下文窗口中。
-
会话存储(即智能体引擎会话、Spanner、Redis):存储会话的逐轮对话。原始对话将被摄入记忆管理器以生成记忆。
-
记忆管理器(例如,智能体引擎记忆库、Mem0、Zep):处理记忆的存储、检索和压缩。存储和检索记忆的机制取决于所使用的提供者。这是识别潜在记忆的智能体所使用的专业服务或组件,它处理记忆的整个生命周期。
• 提取从源数据中提炼关键信息。 • 整合对记忆进行编纂以合并重复实体。 • 存储 将记忆持久化到持久数据库中。 • 检索检索相关记忆以为新交互提供上下文
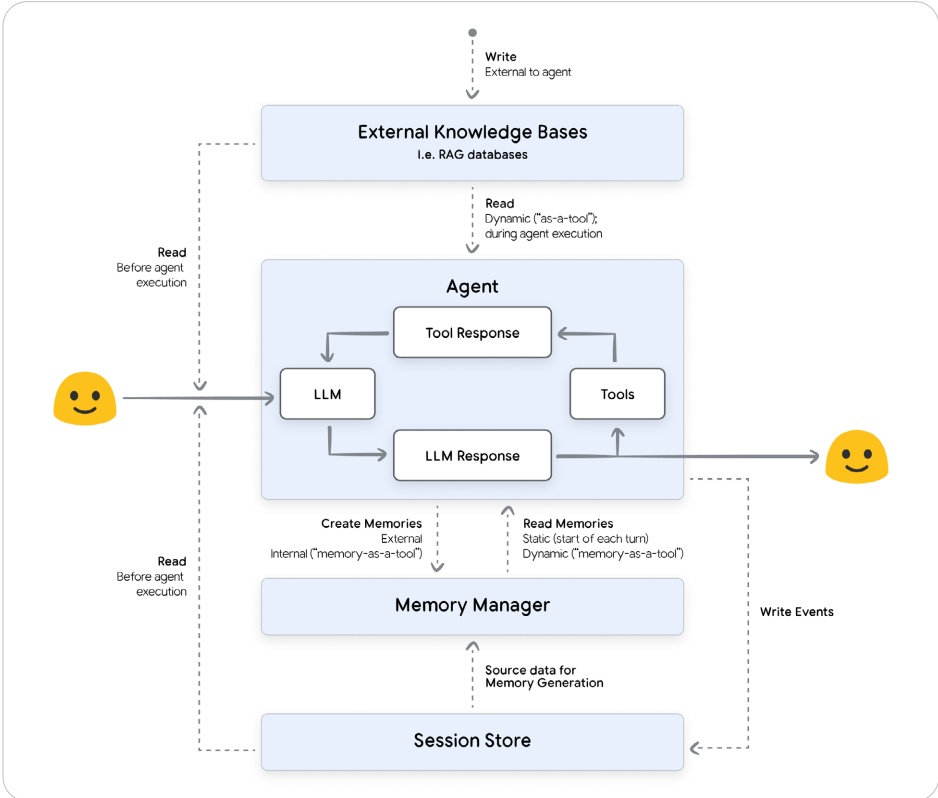
责任划分确保开发者能够专注于Agent的独特逻辑,无需构建复杂的基础基础设施来处理记忆的持久化和管理。重要的是要认识到,记忆管理器是一个活跃的系统,而不仅仅是一个被动的向量数据库。虽然它使用相似性搜索进行检索,但其核心价值在于其能够智能地提取、整合和编纂记忆,随着时间的推移不断优化。像Agent Engine Memory Bank这样的管理型记忆服务,处理记忆生成和存储的整个生命周期,让您能够专注于Agent的核心逻辑。
这种检索能力也是为什么记忆经常被比作另一个关键架构模式:检索增强生成(RAG)。然而,它们基于不同的架构原则,因为RAG处理静态的外部数据,而记忆则编纂动态的用户特定上下文。它们扮演着两个不同且互补的角色:RAG使Agent成为事实的专家,而记忆则使Agent成为用户的专家。以下图表详细说明了它们在高级别上的差异:
| RAG 引擎 | 记忆管理器 | |
| 主要目标 | 将外部、事实性知识注入上下文 | 创建个性化的状态化体验。Agent 会记住事实,随着时间的推移适应用户,并维持长期上下文。 |
| 数据源 | 静态、预先索引的外部知识库(例如,PDF、维基、文档、API)。 | 用户与 Agent 之间的对话。 |
| 隔离级别 | 通常共享。知识库通常是全局的、只读资源,所有用户都可以访问,以确保提供一致、事实性的答案。 | 高度隔离:记忆几乎总是按用户范围划分,以防止数据泄露。 |
| 信息类型 | 静态、事实性和权威性。通常包含特定领域的数据、产品详情或技术文档。 | 动态且(通常)与用户特定的。记忆是从对话中提取的,因此存在固有的不确定性。 |
| 写入模式 | 批量处理,通过离线、管理操作触发。 | 基于事件的处理,在某个时间间隔(例如,每轮或会话结束时)触发或作为工具的记忆(Agent 决定生成记忆)。 |
| 读取模式 | RAG 数据几乎总是以“工具”的形式检索。当 Agent 认为用户的查询需要外部信息时,会检索信息。 | 有两种常见的读取模式:·作为工具的记忆:当用户的查询需要关于用户(或某些其他身份)的更多信息时检索。·静态检索:每次轮换开始时总是检索记忆。 |
| 数据格式 | 自然语言的“块”。 | 自然语言片段或结构化配置文件。 |
| 数据准备 | 分块和索引:将源文档分解成更小的块,然后将这些块转换为嵌入并存储以快速查找。 | 提取和整合:从对话中提取关键细节,确保内容不重复或相互矛盾。 |
理解差异的一个有用方法是认为 RAG 是 Agent 的研究图书馆员,而记忆管理器则是其个人助理。
研究图书馆员(RAG)在一个充满百科全书、教科书和官方文件的庞大公共图书馆中工作。当 Agent 需要一个既定事实——比如产品的技术规格或历史日期——它会咨询图书馆员。图书馆员从这个静态、共享和权威的知识库中检索信息,以提供一致、事实性的答案。图书馆员是关于世界事实的专家,但他们对提问的用户一无所知。
与个人助理(记忆)相比,Agent 跟随 Agent 并携带一个私人笔记本,记录与特定用户每次互动的详细信息。这个笔记本是动态的且高度隔离的,包含个人偏好、过去的对话和不断发展的目标。当 Agent 需要回忆用户的喜爱运动队或上周项目讨论的上下文时,它会转向助理。助理的专长不在于全局事实,而在于用户本身。
最终,一个真正智能的 Agent 需要两者兼备。RAG 为其提供对世界的专业知识,而记忆则为它提供对所服务用户的深入了解。
下一节通过考察其核心组件来分解记忆的概念:存储的信息类型、组织模式、存储和创建机制、战略定义的范围以及处理多模态与文本数据的方式。
4.1 记忆类型
Agent 的记忆可以根据信息的存储方式和捕获方式来分类。这些不同类型的记忆共同创造了对用户及其需求的丰富、上下文化的理解。在所有类型的记忆中,记忆是描述性的,而不是预测性的。
“记忆”是记忆管理器返回的原子上下文片段,由 Agent 作为上下文使用。虽然具体的模式可能有所不同,但单个记忆通常由两个主要组件组成:内容和元数据。
内容是记忆的实质,它从源数据(即会话的原始对话)中提取出来。关键的是,内容旨在框架无关,使用任何 Agent 都可以轻松摄入的简单数据结构。内容可以是结构化或非结构化数据。结构化记忆包括通常存储在通用格式(如字典或 JSON)中的信息。其模式通常由开发者定义,而不是特定框架。例如,{"seat_preference": "Window"}。非结构化记忆是捕捉较长交互、事件或主题本质的自然语言描述。例如,“用户更喜欢靠窗的座位。”
元数据提供了关于记忆的上下文信息,通常存储为简单的字符串。这可以包括记忆的唯一标识符、记忆“所有者”的标识符以及描述内容或数据源的标签。
信息类型
除了基本结构之外,记忆可以根据它们代表的根本知识类型进行分类。这种区分对于理解 Agent 如何使用记忆至关重要,它将记忆分为两个主要的功能类别,这些类别源于认知科学 $^{11}$:陈述性记忆(“知道什么”)和程序性记忆(“知道如何”)。
陈述性记忆是 Agent 对事实、数字和事件的知识。这是 Agent 可以明确陈述或“声明”的所有信息。如果记忆是对“什么”问题的回答,那么它是陈述性的。这个类别包括一般世界知识(语义)和特定用户事实(实体/事件)。
程序性记忆是 Agent 对技能和工作流程的知识。它通过隐式演示如何正确执行任务来指导 Agent 的行动。如果记忆有助于回答“如何”问题——比如预订旅行的正确工具调用序列——那么它是程序性的。
组织模式
一旦创建记忆,下一个问题是如何组织它。记忆管理器通常采用以下一种或多种模式来组织记忆:集合 $^{12}$、结构化用户配置文件或“滚动摘要”。这些模式定义了单个记忆如何相互关联以及如何与用户关联。
收集模式将内容组织成多个自包含的自然语言记忆,供单个用户使用。每个记忆都是一个独特的事件、摘要或观察,尽管对于单个高级主题,集合中可能包含多个记忆。集合允许存储和搜索与特定目标或主题相关的更大、结构更少的信息池。
结构化用户配置文件模式将记忆组织为一组关于用户的核心理念,例如一个不断更新新、稳定信息的联系卡。它旨在快速查找关键、事实性信息,如姓名、偏好和账户详情。
与结构化用户配置文件不同,“滚动”摘要模式将所有信息整合到一个单一、不断演变的记忆中,该记忆代表了用户-代理关系的自然语言摘要。而不是创建新的、单独的记忆,管理者持续更新这个主文档。这种模式常用于压缩长会话,在管理整体令牌计数的同时保留关键信息。
存储架构
此外,存储架构是一个关键决策,它决定了代理如何快速、智能地检索记忆。架构的选择定义了代理是否擅长发现概念上相似的想法、理解结构化关系,或者两者兼而有之。
记忆通常存储在向量数据库和/或知识图中。向量数据库有助于找到与查询概念上相似的记忆。知识图将记忆存储为实体(节点)及其关系(边)的网络。
向量数据库是最常见的做法,它通过语义相似性而不是精确关键词来实现检索。记忆被转换为嵌入向量,数据库找到与用户查询最接近的概念匹配。这擅长检索非结构化、自然语言记忆,其中上下文和意义是关键(即“原子事实” $^{14}$)。
知识图用于将记忆存储为实体(节点)及其关系(边)的网络。检索涉及遍历此图以找到直接和间接连接,使代理能够推理不同事实之间的联系。它适用于结构化、关系查询和理解数据中的复杂连接(即“知识三元组” $^{15}$)。
您还可以通过丰富知识图的标准化实体以向量嵌入的方式将两种方法结合起来,形成混合方法。这使系统能够同时执行关系和语义搜索。这提供了图的结构化推理和向量数据库的细微、概念性搜索,提供了两者的最佳结合。
创建机制
我们还可以根据记忆的创建方式对记忆进行分类,包括信息是如何推导出来的。显式记忆是在用户直接命令代理记住某事时创建的(例如,“记住我的纪念日是10月26日”)。另一方面,当代理在没有直接命令的情况下从对话中推断和提取信息时,会创建隐式记忆(例如,“我的纪念日下周就到了。你能帮我为我伴侣找份礼物吗?”)
记忆还可以根据记忆提取逻辑是否位于代理框架内部或外部来区分。内部记忆是指直接构建到代理框架中的记忆管理。它便于入门,但通常缺乏高级功能。内部记忆可以使用外部存储,但生成记忆的机制在代理内部。
外部记忆涉及使用一个独立的、专门用于记忆管理的服务(例如,Agent Engine Memory Bank、MemO、Zep)。代理框架通过调用此外部服务来存储、检索和处理记忆。这种方法提供了更高级的功能,如语义搜索、实体提取和自动摘要,将记忆管理的复杂任务卸载到专门构建的工具上。
记忆范围
您还需要考虑记忆描述的是谁或什么。这会影响您使用哪个实体(即用户、会话或应用程序)来聚合和检索记忆。
用户级范围是最常见的实现方式,旨在为每个个体创建一个连续、个性化的体验;例如,“用户更喜欢中间座位。”记忆与特定的用户ID相关联,并跨越所有会话持续存在,使代理能够构建对用户偏好和历史的长期理解。
会话级范围旨在压缩长对话;例如,“用户在2025年11月7日至11月14日期间在纽约和巴黎之间购票。他们更喜欢直飞和中间座位。”它创建了一个持久记录,记录了从单个会话中提取的见解,使代理能够用简洁的关键事实集替换冗长、标记密集的对话记录。关键的是,这种记忆与原始会话日志不同;它仅包含对话的处理见解,而不是对话本身,其上下文仅限于该特定会话。
应用级范围(或全局上下文)是所有应用程序用户可访问的记忆;例如,“代号XYZ指的是项目....”此范围用于提供共享上下文、广播系统级信息或建立共同知识的基线。应用级记忆的常见用例是程序性记忆,为代理提供“如何做”的说明;这些记忆通常旨在帮助代理为所有用户进行推理。确保这些记忆被清理掉所有敏感内容,以防止用户之间的数据泄露至关重要。
多模态记忆
“多模态记忆”是一个关键概念,描述了代理如何处理非文本信息,如图像、视频和音频。关键是要区分记忆来源的数据(其来源)和记忆存储的数据(其内容)。
来自多模态来源的记忆是最常见的实现方式。代理可以处理各种数据类型——文本、图像、音频——但创建的记忆是从该来源提取的文本见解。例如,代理可以处理用户的语音备忘录以创建记忆。它不存储音频文件本身;相反,它转录音频并创建一个文本记忆,如“用户对最近的发货延误表示了不满。”
具有多模态内容的记忆是一种更高级的方法,其中记忆本身包含非文本媒体。代理不仅描述内容,还直接存储内容。例如,用户可以上传一张图片并说“记住这个用于我们标志的设计。”代理创建一个直接包含图像文件的记忆,与用户的请求相关联。
大多数当代记忆管理器专注于处理多模态来源并生成文本内容。这是因为为特定记忆生成和检索非结构化二进制数据(如图像或音频)需要专门的模型、算法和基础设施。将所有输入转换为通用、可搜索的格式(文本)要简单得多。
例如,您可以使用Agent Engine Memory Bank从多模态输入生成记忆。输出记忆将是来自内容的内容提取的文本见解:
from google.genai import types
client = vertexai.Client(project=..., location=...)
response = client.agent_engines.memories.generate(
name=agent_engine_name,
direct_contents_source={
"events": [
{
"content": types.Content(
role="user",
parts=[
types.Part.from_text(
"This is context about the multimodal input."
),
types.Part.from_bytes(
data=CONTENT_AS_BYTES,
mime_type=MIME_TYPE
),
types.Part.from_uri(
file_uri="file/path/to/content",
mime_type=MIME_TYPE
)
]
)
}
]
},
scope={"user_id": user_id}
)
下一节将探讨记忆生成的机制,详细说明两个核心阶段:从源数据中提取新信息,以及随后将该信息与现有记忆库的整合。
4.2 记忆生成:提取与整合
记忆生成能够自主地将原始对话数据转换为结构化、有意义的洞察,其工作原理类似于由大语言模型(LLM)驱动的 ETL(提取、转换、加载)管道,旨在提取和浓缩记忆。记忆生成的 ETL 管道将记忆管理器与 RAG 引擎和传统数据库区分开来。
记忆管理器不需要开发者手动指定数据库操作,而是利用 LLM 智能地决定何时添加、更新或合并记忆。这种自动化是记忆管理器的核心优势;它抽象化了管理数据库内容、链式调用 LLM 和部署数据处理后台服务的复杂性。

尽管具体算法因平台而异(例如,Agent Engine Memory Bank、MemO、Zep),但记忆生成的高级过程通常遵循以下四个阶段:
- 摄取:过程始于客户端向记忆管理器提供原始数据源,通常是会话历史记录。
- 提取与过滤:记忆管理器使用大语言模型(LLM)从源数据中提取有意义的内容。关键在于,这个LLM不会提取所有内容;它只捕捉符合预定义主题定义的信息。如果摄取的数据中不包含与这些主题匹配的信息,则不会创建记忆。
- 整合:这是最复杂的阶段,记忆管理器负责处理冲突解决和去重。它执行一个“自我编辑”的过程,使用LLM将新提取的信息与现有记忆进行比较。为确保用户的知识库保持连贯、准确,并随着新信息的出现而不断演变,管理器可以决定:
- 将新的见解合并到现有记忆中。
- 如果现有记忆已失效,则删除现有记忆。
- 如果主题新颖,则创建全新的记忆。
- 存储:最后,新的或更新的记忆被持久化到耐用的存储层(如向量数据库或知识图谱),以便在未来交互中检索。
类似于Agent Engine Memory Bank这样的托管记忆管理器,完全自动化了这一流程。它们提供了一个单一、连贯的系统,将对话噪音转化为结构化知识,使开发者能够专注于代理逻辑,而不是自己构建和维护底层数据基础设施。例如,只需通过简单的API调用即可使用Memory Bank触发记忆生成 $ ^{17} $ :
from google.cloud import vertexai
client = vertexai.Client(project=..., location=...)
client.agent_engines.memories.generate(
name="projects/.../locations/...reasoningEngines/...",
scope={"user_id": "123"},
direct_contents_source={
"events": [...]
},
config={
# Run memory generation in the background.
"wait_for_completion": False
}
)
记忆生成过程可以比作一位勤勉的园丁照料花园。提取记忆就像收到新的种子和树苗(来自对话的新信息)。园丁不会随意地将它们扔到土地上。相反,他们会通过以下方式进行巩固:拔除杂草(删除冗余或冲突的数据)、修剪过长的枝条以改善现有植物的健康(精炼和总结现有记忆),然后将新的树苗种植在最佳位置。这种持续、细致的照料确保花园始终保持健康、有序,并随着时间的推移继续繁荣,而不是变成一片杂乱无章、无法使用的混乱之地。这一异步过程在后台进行,确保花园始终为下一次访问做好准备。
现在,让我们深入了解记忆生成的两个关键步骤:提取和巩固。
深入探讨:记忆提取
记忆提取的目标是回答一个基本问题:“这次对话中哪些信息足够有意义,可以成为记忆?”这不仅仅是简单的总结;而是一个有针对性的、智能的过滤过程,旨在将信号(重要事实、偏好、目标)与噪声(客套话、填充文字)区分开来。
“有意义”不是一个普遍的概念;它完全由代理的目的和使用场景来定义。客户支持代理需要记住的(例如,订单号码、技术问题)与个人健康教练需要记住的(例如,长期目标、情绪状态)在本质上是不同的。因此,定制要保留的信息是创建真正有效代理的关键。
记忆管理器的大语言模型(LLM)通过遵循精心构建的程序性护栏和指令来决定提取什么内容,这些指令通常嵌入在一个复杂的系统提示中。这个提示通过为LLM提供一系列主题定义来定义“有意义”的含义。使用模式和模板的提取,LLM被给予一个预定义的JSON模式或使用LLM功能(如结构化输出)的模板;LLM被指示使用对话中的相应信息构建JSON。或者,使用自然语言主题定义,LLM被一个简单的自然语言主题描述所引导。
在少样本提示中,LLM“展示”了要提取的信息,使用示例。提示包括几个输入文本的示例和理想的、高保真的记忆提取。LLM从示例中学习所需的提取模式,这使得它对于难以用模式或简单定义描述的定制或细微主题非常有效。
大多数记忆管理器默认通过查找常见主题(如用户偏好、关键事实或目标)来工作。许多平台还允许开发者定义自己的自定义主题,将提取过程定制到他们的特定领域。例如,您可以通过提供自己的主题定义和少样本示例来定制Agent Engine 记忆银行认为有意义的、需要持久化的信息:
from google.genai.types import Content, Part
# See https://cloud.google.com/agent-builder/agent-engine/memory-bank/set-up for more information.
memory_bank_config = {
"customization_configs": [
{
"memory_topics": [
{
"managed_memory_topic": {"managed_topic_enum": "USER_PERSONAL_INFO"}
}
]
}
],
"custom_memory_topic": {
"label": "business_feedback",
"description": "Specific user feedback about their experience at the coffee shop. This includes opinions on drinks, food, pastries, ambiance, staff friendliness, service speed, cleanliness, and any suggestions for improvement."
},
"generate_memories_examples": {
"conversationSource": {
"events": [
{
"content": Content(
role="model",
parts=[Part(text="Welcome back to The Daily Grind! We'd love to hear your feedback on your visit.")]
)
},
{
"content": Content(
role="user",
parts=[Part(text="Hey. The drip coffee was a bit lukewarm today, which was a bummer. Also, the music was way too loud, I could barely hear my friend.")]
)}
{
"generatedMemories": [
{"fact": "The user reported that the drip coffee was lukewarm."},
{"fact": "The user felt the music in the shop was too loud."}
]
}
]
}
}
}
agent_engine = client.agent_engines.create(
config={
"context_spec": {"memory_bank_config": memory_bank_config}
}
)
Snippet 7: 自定义Agent引擎记忆银行认为有意义的持久化信息
尽管记忆提取本身并非“摘要”,但算法可能会结合摘要功能来提炼信息。为了提高效率,许多记忆管理器将对话的滚动摘要直接整合到记忆提取的Prompt $ ^{20} $ 。这段压缩的历史记录提供了从最近交互中提取关键信息的必要上下文。它消除了每次轮次都需要重复处理完整、冗长的对话以维持上下文的必要性。
一旦从数据源中提取了信息,就必须通过整合来更新现有的记忆库,以反映新的信息。
深入探讨:记忆整合
在从冗长的对话中提取记忆之后,整合应将新信息整合到一个连贯、准确且不断发展的知识库中。这可以说是记忆生命周期中最复杂的阶段,它将简单的事实集合转化为对用户的精心理解。没有整合,代理的记忆将迅速变成一个嘈杂、矛盾且不可靠的信息记录。这种“自我管理”通常由大语言模型(LLM)管理,这也是将记忆管理器提升为简单数据库之上的关键。
整合解决了由对话数据引起的根本问题,包括:
- 信息重复:用户可能在不同的对话中以多种方式提及相同的事实(例如,“我需要飞往纽约的航班”和后来“我正在计划去纽约的旅行”)。简单的提取过程将创建两个冗余的记忆。
- 信息冲突:用户的状态会随时间变化。如果没有整合,代理的记忆将包含相互矛盾的事实。
- 信息演变:一个简单的事实可能会变得更加复杂。最初关于“用户对营销感兴趣”的记忆可能会演变为“用户正在领导一个专注于第四季度客户获取的营销项目”。
- 记忆相关性衰减:并非所有记忆都永远有用。代理必须进行遗忘——主动剪枝旧、过时或低置信度的记忆,以保持知识库的相关性和效率。遗忘可以通过在整合期间指示LLM参考新信息或通过自动删除(TTL)来实现。
整合过程是一个由LLM驱动的流程,它将新提取的见解与用户的现有记忆进行比较。首先,该流程尝试检索与新提取的记忆相似的现有记忆。这些现有记忆是整合的候选者。如果现有记忆与新信息相矛盾,则可能被删除。如果它得到了增强,则可能被更新。
其次,LLM被呈现现有记忆和新信息。其核心任务是分析它们并确定应执行的操作。主要操作包括:
- 更新:使用新或更正的信息修改现有记忆。
- 创建:如果新的见解完全新颖且与现有记忆无关,则创建一个新的记忆。
- 删除/无效化:如果新信息使旧记忆完全无关或错误,则删除或使其无效。
最后,记忆管理器将LLM的决定转换为更新记忆存储的事务。
记忆溯源
经典机器学习的“垃圾输入,垃圾输出”原则在大语言模型(LLM)中尤为重要,其结果往往是“垃圾输入,自信的垃圾输出”。为了使Agent能够做出可靠的决策,以及使记忆管理器能够有效地巩固记忆,它们必须能够批判性地评估自身记忆的质量。这种可靠性直接来源于记忆的来源——一个详细的记录其起源和历史的记录。

图7:数据源与记忆之间的信息流。单个记忆可以由多个数据源推导而来,而单个数据源也可能对多个记忆做出贡献。
记忆巩固的过程——将来自多个来源的信息合并成一个不断演变的单一记忆——产生了追踪其来源的需求。如图所示,一个单一的记忆可能是由多个数据源混合而成的,而单个数据源也可能被分割成多个记忆。
为了评估可靠性,Agent必须跟踪每个来源的关键细节,例如其来源(来源类型)和年龄(新鲜度)。这些细节之所以至关重要,有两个原因:它们决定了每个来源在记忆巩固过程中的权重,并告知Agent在推理过程中应依赖该记忆的程度。
来源类型是决定信任度最重要的因素之一。数据源主要分为以下三类:
- 自举数据:从内部系统(如CRM)预先加载的信息。这种高信任度的数据可以用来初始化用户的记忆,以解决冷启动问题,即向Agent从未互动过的用户提供个性化体验的挑战。
- 用户输入:这包括通过表单等明确提供的数据(高信任度)或从对话中隐式提取的信息(通常信任度较低)。
- 工具输出:来自外部工具调用的数据。从工具输出生成记忆通常是不被鼓励的,因为这些记忆往往脆弱且过时,使得这种来源类型更适合短期缓存。
在记忆管理中考虑记忆来源
这种动态的多来源记忆方法在管理记忆时产生了两个主要的操作挑战:冲突解决和删除派生数据。
记忆巩固不可避免地会导致冲突,其中一个数据源与另一个数据源发生冲突。记忆的来源允许记忆管理器为其信息来源建立信任等级。当来自不同来源的记忆相互矛盾时,Agent必须使用这个等级在冲突解决策略中。常见的策略包括优先考虑最可信的来源、优先考虑最新信息,或在不同数据点之间寻找证实。
管理记忆的另一个挑战发生在删除记忆时。一个记忆可以由多个数据源推导而来。当用户撤销对某个数据源的访问权限时,从该数据源派生出的数据也应被删除。删除被该来源“触及”的每个记忆可能过于激进。一种更精确但计算成本更高的方法是,仅使用剩余的有效来源,从头开始重新生成受影响的记忆。
除了静态的来源细节之外,对记忆的信心也必须不断演变。信心通过证实而增加,例如当多个可信来源提供一致信息时。然而,一个高效的记忆系统还必须通过记忆修剪——一个识别并“遗忘”不再有用的记忆的过程——来积极管理其现有知识。这种修剪可以由几个因素触发。
- 基于时间的衰减:记忆的重要性可能会随时间而降低。关于两年前会议的记忆可能不如上周的记忆相关。
- 信心低:由弱推理创建且从未被其他来源证实的记忆可能被修剪。
- 不相关性:随着Agent对用户有更深入的了解,它可能会确定一些较旧且微不足道的记忆不再与用户的当前目标相关。
通过结合反应式巩固管道和主动修剪,记忆管理器确保代理的知识库不仅仅是一个记录了所有说过的话的日志。相反,它是对用户的一种精心挑选、准确且相关的理解。
在推理过程中考虑记忆谱系
除了在整理语料库内容时考虑记忆的谱系外,在推理时还应考虑记忆的可靠性。代理对记忆的信心不应是静态的;它必须根据新信息和时间的推移而演变。信心通过证实而增加,例如当多个可信来源提供一致信息时。相反,随着时间的推移,旧的记忆变得陈旧,信心(或衰减)也会下降,当引入矛盾信息时,信心也会下降。最终,系统可以通过存档或删除低信心记忆来“忘记”。这种动态的信心分数在推理时至关重要。记忆及其信心分数不会直接展示给用户,而是注入到提示中,使大语言模型能够评估信息可靠性并做出更细微的决定。
整个信任框架服务于代理的内部推理过程。记忆及其信心分数通常不会直接展示给用户。相反,它们被注入到系统提示中,允许大语言模型权衡证据,考虑其信息的可靠性,并最终做出更细微且可靠的决策。
触发记忆生成
虽然一旦触发生成,记忆管理器会自动化记忆提取和巩固,但代理仍需决定何时尝试生成记忆。这是一个关键的建筑选择,需要在数据新鲜度、计算成本和延迟之间取得平衡。这个决定通常由代理的逻辑来管理,它可以采用几种触发策略。记忆生成可以根据各种事件启动:
• 会话完成:在多轮会话结束时触发生成。 • 轮次节奏:在特定数量的轮次后运行该过程(例如,每5轮)。 • 实时:在每次轮次后生成记忆。 • 明确命令:在直接用户命令(例如,“记住这个”)下激活该过程。
触发选择涉及成本和保真度之间的直接权衡。频繁生成(例如,实时)确保记忆非常详细且新鲜,捕捉到对话的每一个细微之处。然而,这会带来最高的LLM和数据库成本,并且如果不妥善处理,可能会引入延迟。不频繁生成(例如,在会话完成时)成本效益更高,但风险是创建低保真度的记忆,因为LLM必须一次性总结更大的对话块。您还应注意,记忆管理器不要多次处理相同的事件,因为这会引入不必要的成本。
记忆作为工具
一种更复杂的方法是允许代理自行决定何时创建记忆。在这种模式中,记忆生成被公开为一个工具(即create_memory);工具定义应定义应考虑哪些类型的信息是有意义的。然后,代理可以分析对话,并自主决定在识别到有意义的信息时调用此工具。这将从外部记忆管理器将识别“有意义信息”的责任转移到代理(以及您作为开发者)本身。
例如,您可以使用ADK通过将您的记忆生成代码打包成一个工具$^{21}$,代理在认为对话有意义时决定调用它。您可以将会话发送到记忆银行,记忆银行将提取和巩固对话历史中的记忆:
from google.adk.agents import LlmAgent
from google.adk.memory import VertexAiMemoryBankService
from google.adk.runners import Runner
from google.adk.tools import ToolContext
def generate_memories(tool_context: ToolContext):
"""Triggers memory generation to remember the session."""
# Option 1: Extract memories from the complete conversation history using the
# ADK memory service.
tool_context._invocation_context.memory_service.add_session_to_memory(
session)
# Option 2: Extract memories from the last conversation turn.
client.agent_engines.memories.generate(
name="projects/.../locations/...reasoningEngines/...",
direct_contents_source={
"events": [
{"content": tool_context._invocation_context.user_content}
]
},
scope={
"user_id": tool_context._invocation_context.user_id,
"app_name": tool_context._invocation_context.app_name
},
# Generate memories in the background
config={"wait_for_completion": False}
)
return {"status": "success"}
agent = LlmAgent(
...,
tools=[generate_memories]
)
runner = Runner(
agent=agent,
app_name=APP_NAME,
session_service=session_service,
memory_service=VertexAiMemoryBankService(
agent_engine_id=AGENT_ENGINE_ID,
project=PROJECT,
location=LOCATION
)
)
片段 8:使用自定义工具触发记忆生成的 ADK 代理。记忆库将提取并整合这些记忆。
另一种方法是利用内部记忆,其中代理主动决定从对话中记住什么。在这个工作流程中,代理负责提取关键信息。可选地,这些提取的记忆随后会被发送到代理引擎记忆库,与用户现有的记忆进行整合 $^{22}$。
def extract_memories(query: str, tool_context: ToolContext):
"""Triggers memory generation to remember information.
Args:
query: Meaningful information that should be persisted about the user.
"""
client_agent_engines.memories.generate(
name="projects/.../locations/...reasoningEngines/...",
# The meaningful information is already extracted from the conversation, so we
# just want to consolidate it with existing memories for the same user.
direct_memories_source = {
"direct_memories": [{"fact": query}]
},
scope = {
"user_id": tool_context._invocation_context.user_id,
"app_name": tool_context._invocation_context.app_name
},
config = {"wait_for_completion": False}
)
return {"status": "success"}
agent = LlmAgent(
...,
tools=[extract_memories]
)
片段 9:使用自定义工具从对话中提取记忆并与 Agent Engine 记忆库触发巩固的大语言模型(LLM)Agent。与片段 8 不同,Agent 负责提取记忆,而不是记忆库。
背景操作与阻塞操作对比
记忆生成是一个昂贵的操作,需要调用 LLM 和数据库写入。对于生产环境中的 Agent,记忆生成几乎总是应该异步作为后台进程处理 $^{23}$。
Agent 向用户发送响应后,记忆生成管道可以并行运行,而不会阻塞用户体验。这种解耦对于保持 Agent 的快速和响应性至关重要。如果采用阻塞(或同步)方法,用户必须等待记忆写入才能收到响应,这将导致无法接受的缓慢和令人沮丧的用户体验。这要求记忆生成发生在与 Agent 核心运行时架构分离的服务中。
4.3 记忆检索
在建立记忆生成机制后,您的关注点可以转向关键任务——检索。一个智能的检索策略对于 Agent 的性能至关重要,这包括决定哪些记忆应该被检索以及何时检索它们。
检索记忆的策略很大程度上取决于记忆的组织方式。对于结构化的用户配置文件,检索通常是对整个配置文件或特定属性的简单查找。然而,对于记忆集合,检索则是一个更为复杂的搜索问题。目标是从一个大量非结构化或半结构化的数据中找到最相关、概念上相关的信息。本节中讨论的策略旨在解决记忆集合的复杂检索挑战。
记忆检索旨在寻找当前对话中最相关的记忆。一个有效的检索策略至关重要;提供不相关的记忆可能会使模型困惑并降低其响应质量,而找到完美的上下文信息则可能导致令人瞩目的智能交互。核心挑战是在严格的延迟预算内平衡记忆的“有用性”。
高级记忆系统不仅超越了简单的搜索,还会从多个维度对潜在的记忆进行评分,以找到最佳匹配。
- 相关性(语义相似度):这个记忆与当前对话在概念上有多相关?
- 近期性(基于时间):这个记忆是何时创建的?
- 重要性(显著性):这个记忆总体上有多重要?与相关性不同,“重要性”可能在生成时定义。
仅依赖于基于向量的相关性是一个常见的陷阱。相似度分数可能会显示概念上相似但过时或微不足道的记忆。最有效的策略是结合这三个维度的分数。
对于精度至关重要的应用,可以使用查询重写、重新排序或专用检索器等技术来细化检索。然而,这些技术计算成本高昂,会增加显著的延迟,因此对于大多数实时应用来说并不适用。对于需要这些复杂算法且记忆不会很快过时的场景,缓存层可以是一个有效的缓解措施。缓存允许将检索查询的昂贵结果临时存储,从而绕过后续相同请求的高延迟成本。
使用查询重写,大语言模型(LLM)可以用于改进搜索查询本身。这可以包括将用户的模糊输入重写为更精确的查询,或者将单个查询扩展为多个相关查询,以捕捉主题的不同方面。虽然这显著提高了初始搜索结果的质量,但它增加了在过程开始时额外调用LLM的延迟。
使用重新排序,初始检索通过相似性搜索获取一组广泛的候选记忆(例如,前50个结果)。然后,LLM可以重新评估并重新排序这个较小的集合,以生成更准确的最终列表 $ ^{24} $ 。
最终,您可以使用微调训练一个专门的检索器。然而,这需要访问标记数据,并且可能会显著增加成本。最终,检索的最佳方法始于更好的记忆生成。确保记忆语料库高质量且无无关信息是确保任何检索的记忆集合都有用的最有效方式。
检索时机
检索的最终架构决策是在何时检索记忆。一种方法是主动检索,即在每次回合开始时自动加载记忆。这确保了上下文始终可用,但为不需要记忆访问的回合引入了不必要的延迟。由于记忆在单个回合中保持静态,因此可以有效地缓存以减轻这种性能成本。
例如,您可以使用ADK中的内置PreloadMemoryTool或自定义回调实现主动检索 $ ^{25} $ :
# Option 1: Use the built-in PreloadMemoryTool which retrieves memories with similarity search every turn.
agent = LlmAgent(
...
tools=[adk.tools.preload_memory_tool.PreloadMemoryTool()]
)
# Option 2: Use a custom callback to have more control over how memories are retrieved.
def retrieve_memories_callback(callback_context, llm_request):
user_id = callback_context._invocation_context.user_id
app_name = callback_context._invocation_context.app_name
response = client.agent_engines.memories.retrieve(
name="projects/.../locations/...reasoningEngines/...",
scope={
"user_id": user_id,
"app_name": app_name
}
)
memories = [f"*{memory.memory.fact}" for memory in list(response)]
if not memories:
# No memories to add to System Instructions.
return
# Append formatted memories to the System Instructions
llm_request.config.system_instruction += "\nHere is information that you have about the user:\n"
llm_request.config.system_instruction += "\n".join(memories)
agent = LlmAgent(
...
before_model_callback=retrieve_memories_callback,
)
或者,您还可以使用反应式检索(“记忆作为工具”),其中代理被赋予查询其记忆的工具,自行决定何时检索上下文。这种方法更高效且更稳健,但需要额外的 LLM 调用,这会增加延迟和成本;然而,只有在必要时才会检索记忆,因此延迟成本发生的频率较低。此外,代理可能不知道是否存在需要检索的相关信息。但是,通过让代理了解可用的记忆类型(例如,如果您使用的是自定义工具,则在工具描述中),可以使其做出更明智的查询决策。
# Option 1: Use the built-in LoadMemory.
agent = LlmAgent(
...
tools=[adk.tools.load_memory_tool.LoadMemoryTool()],
)
# Option 2: Use a Custom tool where you can describe what type of information
# might be available.
def load_memory(query: str, tool_context: ToolContext):
"""Retrieves memories for the user.
The following types of information may be stored for the user:
* User preferences, like the user's favorite foods.
...
"""
# Retrieve memories using similarity search.
response = tool_context.search_memory(query)
return response.memories
agent = LlmAgent(
...
tools=[load_memory],
)
片段 11:配置您的 ADK 代理以决定何时使用内置或自定义工具检索记忆
基于记忆的推理
一旦检索到相关记忆,下一步就是策略性地将它们放置到模型的上下文窗口中。这是一个关键过程;记忆的放置可以显著影响大语言模型的推理,影响运营成本,并最终决定最终答案的质量。
记忆主要通过将其附加到系统指令或注入到对话历史中来进行展示。在实践中,混合策略通常是最高效的。使用系统提示来稳定、全局地存储记忆(如用户配置文件),这些记忆应该始终存在。否则,使用对话注入或记忆作为工具来处理短暂、情景记忆,这些记忆仅与对话的即时上下文相关。这平衡了持久上下文的需求与即时信息检索的灵活性。
系统指令中的记忆
使用记忆进行推理的一个简单选项是将记忆附加到系统指令中。这种方法通过将检索到的记忆直接附加到系统提示旁边,并附带序言,将它们作为整个交互的基础上下文来保持对话历史的整洁。例如,您可以使用 Jinja 动态地将记忆添加到您的系统指令中:
from jinja2 import Template
template = Template("""{{ system_instructions }}
<MEMORIES>
Here is some information about the user:
{{% for retrieved_memory in data %}* {{ retrieved_memory.memory.fact }}
{{% endfor %}</MEMORIES>
""")
prompt = template.render(
system_instructions=system_instructions,
data=retrieved_memories
)
在系统指令中包含记忆赋予记忆高权威性,干净地分离了上下文与对话,非常适合稳定、全局性的信息,例如用户资料。然而,存在过度影响的风险,即Agent可能会试图将每个话题都与核心指令中的记忆联系起来,即使这样做并不合适。
这种架构模式引入了几个约束。首先,它要求Agent框架在每次调用LLM之前支持动态构建系统提示;这种功能并不总是容易实现。此外,该模式与“记忆即工具”不兼容,因为系统提示必须在LLM决定调用记忆检索工具之前最终确定。最后,它处理非文本记忆的能力较差。大多数LLM只接受文本作为系统指令,这使得将图像或音频等多模态内容直接嵌入提示中变得具有挑战性。
对话历史中的记忆
在这种方法中,检索到的记忆直接注入到逐轮对话中。记忆可以放置在完整对话历史之前,或者直接在最新用户查询之前。
然而,这种方法可能会产生噪声,增加令牌成本,并可能使模型混淆,如果检索到的记忆与对话无关。其主要风险是对话注入,即模型可能会错误地将记忆视为实际在对话中说过的内容。您还需要更加小心地考虑注入对话中的记忆的视角;例如,如果您使用的是“用户”角色和用户级记忆,记忆应该以第一人称视角书写。
将记忆注入对话历史的一个特殊情况是通过工具调用检索记忆。这些记忆将直接作为工具输出的一部分包含在对话中。
def load_memory(query: str, tool_context: ToolContext):
"""Loads memories into the conversation history..."
response = tool_context.search_memory(query)
return response.memories
agent = LlmAgent(
...,
tools=[load_memory],
)
4.4 程序性记忆
本白皮书主要关注陈述性记忆,这一关注点与当前的商业记忆格局相呼应。大多数记忆管理平台也都是为此种陈述性方法而构建的,擅长提取、存储和检索“什么”——事实、历史和用户数据。 然而,这些系统并非为管理程序性记忆而设计,程序性记忆是提升智能体工作流程和推理能力的机制。存储“如何”并非一个信息检索问题;它是一个推理增强问题。管理这种“知道如何”需要完全不同的、专门的算法生命周期,尽管在高级结构上具有相似性 $^{26}$:
-
提取:程序性提取需要专门提示,旨在从成功的交互中提炼可重用的策略或“剧本”,而不仅仅是捕捉事实或有意义的信息。
-
巩固:虽然陈述性巩固合并相关事实(“什么”),但程序性巩固则是对工作流程本身(“如何”)进行整理。这是一个积极的逻辑管理过程,专注于将新的成功方法与现有的“最佳实践”相结合,修复已知计划中的缺陷步骤,以及修剪过时或无效的程序。
-
检索:目标不是检索数据来回答问题,而是检索一个指导智能体如何执行复杂任务的计划。因此,程序性记忆可能具有与陈述性记忆不同的数据模式。
智能体能够“自我进化”其逻辑的能力自然引发了对一种常见适应方法的比较:微调——通常通过人类反馈强化学习(RLHF)$^{27}$。虽然这两个过程都旨在改善智能体的行为,但它们的机制和应用是根本不同的。微调是一个相对缓慢的离线训练过程,它改变模型权重。程序性记忆通过动态地将正确的“剧本”注入提示中,引导智能体通过情境学习进行快速在线适应,而无需进行任何微调。
4.5 测试与评估
现在您已经拥有了一个具有记忆功能的智能体,您应该通过全面的质最和评估测试来验证具有记忆功能的智能体的行为。评估智能体的记忆是一个多层次的流程。评估需要验证智能体是否记得正确的事情(质最),是否能够在需要时找到这些记忆(检索),以及使用这些记忆实际上是否有助于它实现目标(任务成功)。虽然学术界关注可复制的基准,但行业评估则集中在记忆如何直接影响生产智能体的性能和可用性。
记忆生成质量指标评估记忆本身的内容,回答的问题是:“智能体是否记得正确的事情?”这通常通过将智能体生成的记忆与手动创建的理想记忆“黄金集”进行比较来衡量。
- 精确度:在智能体创建的所有记忆中,有多少百分比是准确且相关的?高精确度可以防止“过于积极”的记忆系统将无关的噪声污染知识库。
- 召回率:在智能体应该记住的所有相关事实中,有多少百分比被捕捉到了?高召回率确保智能体不会错过关键信息。
- F1分数:精确度和召回率的调和平均值,提供了一个平衡的质量衡量指标。
记忆检索性能指标评估智能体在正确的时间找到正确记忆的能力。
- Recall@K:当需要记忆时,是否能在前'K'个检索结果中找到正确的记忆?这是衡量检索系统准确性的主要指标。
- 延迟:检索是代理响应的“热点路径”。整个检索过程必须在严格的延迟预算内(例如,低于200毫秒)执行,以避免降低用户体验。
端到端任务成功指标是最终测试,回答的问题是:“记忆实际上是否帮助代理更好地完成其工作?” 这通过评估代理使用其记忆在下游任务上的表现来衡量,通常使用一个LLM“裁判”将代理的最终输出与黄金答案进行比较。裁判决定代理的答案是否准确,从而有效衡量记忆系统对最终结果贡献的程度。
评估不是一次性的事件;它是一个持续改进的引擎。上述指标提供了识别弱点并随着时间的推移系统地增强记忆系统的数据。这个迭代过程包括建立基线、分析失败、调整系统(例如,优化提示、调整检索算法),并重新评估以衡量变化的影响。
虽然上述指标侧重于质量,但生产就绪性也取决于性能。对于每个评估领域,关键是要衡量底层算法的延迟和它们在负载下的扩展能力。在“热点路径”上检索记忆可能有一个严格的亚秒级延迟预算。生成和巩固,尽管通常是异步的,但必须有足够的吞吐量以满足用户需求。最终,一个成功的记忆系统必须智能、高效且健壮,适用于现实世界使用。
4.6 记忆的生产考虑因素
除了性能之外,将具有记忆功能的代理从原型过渡到生产还需要关注企业级架构问题。这一转变引入了可扩展性、弹性和安全性的关键要求。一个生产级系统不仅需要设计用于智能,还需要设计用于企业级健壮性。
为确保用户体验不会被记忆生成的计算密集型过程阻塞,一个健壮的架构必须将记忆处理与主应用程序逻辑解耦。虽然这是一个事件驱动模式,但它通常通过直接的非阻塞API调用到一个专用的记忆服务来实现,而不是一个自行管理的消息队列。流程如下: 1. 代理推送数据:在相关事件(例如,会话结束)之后,代理应用程序向记忆管理器发起非阻塞API调用,将原始源数据(如对话记录)"推送"给记忆管理器进行处理。 2. 记忆管理器在后台处理:记忆管理器服务立即确认请求并将生成任务放入其内部管理的队列中。然后,它只负责异步的繁重工作:进行必要的LLM调用以提取、整合和格式化记忆。管理器可能会延迟处理事件,直到一定时间的无活动期过去。 3. 持久化记忆:服务将最终的记忆(可能是新条目或对现有条目的更新)写入一个专用的、耐用的数据库。对于托管记忆管理器,存储是内置的。 4. 代理检索记忆:主代理应用程序可以在需要检索新用户交互的上下文时直接查询这个记忆存储。
基于服务的、非阻塞的方案确保了记忆管道中的故障或延迟不会直接影响到面向用户的应用程序,这使得系统具有更高的容错能力。这也决定了在线(实时)生成(适用于对话的新鲜度)和离线(批量)处理(用于从历史数据中填充系统)之间的选择。
随着应用程序的增长,记忆系统必须能够处理高频事件而不会出现故障。在并发请求的情况下,系统必须防止死锁或竞态条件,当多个事件尝试修改相同的记忆时。您可以使用事务数据库操作或乐观锁定来减轻竞态条件;然而,当多个请求尝试修改相同的记忆时,这可能会引入排队或节流。一个健壮的消息队列对于缓冲高事件量并防止记忆生成服务过载至关重要。
记忆服务还必须能够抵御瞬时错误(故障处理)。如果大语言模型(LLM)调用失败,系统应使用指数退避的重试机制,并将持久性故障路由到死信队列进行分析。
对于全球应用程序,记忆管理器必须使用具有内置多区域复制的数据库,以确保低延迟和高可用性。客户端复制不可行,因为合并需要单个、事务一致的数据视图以防止冲突。因此,记忆系统必须在内部处理复制,向开发者呈现一个单一、逻辑的数据存储,同时确保底层知识库在全球范围内保持一致。
像Agent Engine Memory Bank这样的托管记忆系统应帮助您解决这些生产考虑因素,从而使您能够专注于核心代理逻辑。
隐私和安全风险
记忆是从用户数据中派生出来的,并包含用户数据,因此它们需要严格的隐私和安全控制。一个有用的类比是将系统的记忆想象成一个由专业档案管理员管理的安全企业档案,其任务是保护宝贵的知识同时保护公司。
这个档案的黄金法则就是数据隔离。正如档案管理员永远不会混合来自不同部门的机密文件一样,记忆必须在用户或租户级别上严格隔离。为一位用户服务的代理绝不能访问另一位用户的记忆,这通过限制性的访问控制列表(ACL)来强制执行。此外,用户必须对其数据有程序性控制,并有权明确选择退出记忆生成或请求从档案中删除所有文件。
在归档任何文件之前,档案管理员会执行关键的安全步骤。首先,他们会仔细检查每一页以删除敏感个人信息(PII),确保知识被保存而不产生责任。其次,档案管理员受过训练,能够识别和丢弃伪造或有意误导的文件——这是一种防止记忆中毒的措施。同样,系统必须在将信息提交到长期记忆之前对其进行验证和清理,以防止恶意用户通过提示注入来腐蚀代理的持久知识。系统必须包括像模型盔甲这样的安全措施,在将信息提交到长期记忆之前对其进行验证和清理。
此外,如果多个用户共享同一组记忆,如程序性记忆(教导代理如何做某事),还存在数据泄露的风险。例如,如果一个用户的程序性记忆被用作另一个用户的示例——比如在公司范围内共享备忘录——档案管理员必须首先进行严格的匿名化,以防止敏感信息跨越用户边界泄露。
5. 结论
这份白皮书探讨了上下文工程学科,重点关注其两个核心组件:会话和记忆。从简单的对话回合到持久、可执行智能的旅程,都受到这一实践的影响,该实践涉及动态地将所有必要信息——包括对话历史、记忆和外部知识——组装到LLM的上下文窗口中。整个过程依赖于两个不同但又相互关联的系统之间的相互作用:即时的会话和长期的记忆。
会话管理着“现在”,作为一个低延迟、按时间顺序的容器,用于单个对话。其主要挑战是性能和安全,需要低延迟访问和严格的隔离。为了防止上下文窗口溢出和延迟,你必须使用基于令牌的截断或递归摘要等提取技术,以压缩会话历史或单个请求负载中的内容。此外,安全性至关重要,在会话数据持久化之前必须进行PII(个人身份信息)编辑。
记忆是长期个性化的引擎,是跨多个会话持久化的核心机制。它超越了RAG(使代理成为事实专家)的概念,使代理成为用户专家。记忆是一个由LLM驱动的主动ETL管道——负责提取、整合和检索,从对话历史中提炼出最重要的信息。通过提取,系统将最关键的信息提炼成关键记忆点。随后,整合将新信息与现有语料库进行编纂和整合,解决冲突,删除冗余数据,以确保知识库的一致性。为了保持流畅的用户体验,记忆生成必须在代理响应后作为异步后台进程运行。通过跟踪来源并采取防范记忆中毒等风险的措施,开发者可以构建值得信赖、适应性强的助手,这些助手真正地随着用户的学习和成长。
6. 参考
- https://cloud.google.com/use-cases/retrieval-augmented-generation?hl=en
- https://arxiv.org/abs/2301.00234
- https://cloud.google.com/vertex-ai/generative-ai/docs/agent-engine/sessions/overview
- https://langchain-ai.github.io/langgraph/concepts/multi_agent/#message-passing-between-agents
- https://google.github.io/adk-docs/agents/multi-agents/
- https://google.github.io/adk-docs/agents/multi-agents/#c-explicit-invocation-agenttool
- https://agent2agent.info/docs/concepts/message/
- https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
- https://cloud.google.com/security-command-center/docs/model-armor-overview
- https://ai.google.dev/gemini-api/docs/long-context#long-context-limitations
- https://huggingface.co/blog/Kseniase/memory
- https://langchain-ai.github.io/langgraph/concepts/memory/#semantic-memory
- https://langchain-ai.github.io/langgraph/concepts/memory/#semantic-memory
- https://arxiv.org/pdf/2412.15266
- https://arxiv.org/pdf/2412.15266
- https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/inference#sample-requests-text-gen-multimodal-prompt
- https://cloud.google.com/vertex-ai/generative-ai/docs/agent-engine/memory-bank/generate-memories
- https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/control-generated-output
- https://cloud.google.com/agent-builder/agent-engine/memory-bank/set-up#memory-bank-config
- https://arxiv.org/html/2504.19413v1
- https://google.github.io/adk-docs/tools/#how-agents-use-tools
- https://cloud.google.com/vertex-ai/generative-ai/docs/agent-engine/memory-bank/generate-memories#consolidate-pre-extracted-memories
- https://cloud.google.com/vertex-ai/generative-ai/docs/agent-engine/memory-bank/generate-memories#background-memory-generation
- https://arxiv.org/pdf/2503.08026
- 大语言模型文档 - Google GitHub
- arXiv 论文 - 2508.06433v2
- Google Cloud 上的强化学习与人类反馈 (RLHF) - Google Cloud 博客
- arXiv 论文 - 2503.03704
- 模型装甲概述 - Google Cloud 安全命令中心
- 选择设计模式 - 构建Agent式AI系统 - Google Cloud 架构