第16章:资源感知优化
资源感知优化使智能体能够在运行过程中动态监控和管理计算、时间和财务资源。这与主要关注动作序列的简单规划不同。资源感知优化要求智能体在特定资源预算内实现目标或优化效率时,对动作执行做出决策。这包括在更精确但昂贵的模型和更快、成本更低的模型之间做出选择,或者决定是否为更精细的响应分配额外的计算资源,以换取更快、更简略的回答。
例如,考虑一个被分配分析大量数据集的智能体,用于金融分析师。如果分析师需要立即获得一份初步报告,智能体可能会使用更快、更经济的模型来快速总结关键趋势。然而,如果分析师需要为关键的投资决策进行高度准确的预测,并且有更大的预算和更多的时间,智能体将分配更多资源来利用一个更强大、速度较慢但更精确的预测模型。这类问题的关键策略是回退机制,当首选模型因过载或限制而不可用时,它作为一项保障措施。为确保平稳降级,系统会自动切换到默认或更经济的模型,以保持服务连续性,而不是完全失败。
实际应用与用例
实际应用案例包括:
- 成本优化的LLM使用:一个智能体根据预算限制,决定是否使用大型、昂贵的LLM处理复杂任务,还是使用小型、更经济的LLM处理简单查询。
- 延迟敏感操作: 在实时系统中,智能体选择一条更快但可能不够全面的推理路径,以确保及时响应。
- 能源效率: 对于部署在边缘设备或功率有限的智能体,优化其处理能力以节省电池寿命。
- 服务可靠性的回退机制: 当主选模型不可用时,智能体会自动切换到备用模型,确保服务连续性和优雅降级。
- 数据使用管理: 选择使用摘要数据检索而非完整数据集下载的智能体,以节省带宽或存储空间。
- 自适应任务分配: 在多智能体系统中,智能体根据其当前的计算负载或可用时间自行分配任务。
动手编码示例
一个用于回答用户问题的智能系统可以评估每个问题的难度。对于简单查询,它使用成本效益较高的语言模型,例如Gemini Flash。对于复杂查询,则考虑使用更强大但昂贵的语言模型(如Gemini Pro)。是否使用更强大的模型还取决于资源可用性,特别是预算和时间限制。该系统会动态选择合适的模型。
例如,考虑一个使用分层智能体构建的旅行规划器。高级规划涉及理解用户复杂的请求,将其分解为多步骤行程,并做出逻辑决策,这部分将由一个复杂且功能强大的LLM(大型语言模型)如Gemini Pro来管理。这就是所谓的“规划”智能体,它需要深入理解上下文和推理能力。
然而,一旦计划确立,该计划内的各项任务,如查询航班价格、检查酒店可用性或寻找餐厅评价,本质上都是简单的、重复的网页查询。这些“工具功能调用”可以通过像Gemini Flash这样的更快、更经济的模型来执行。更容易理解为什么这些直接的网页搜索可以使用经济型模型,而复杂的规划阶段则需要更高级模型的大脑智慧,以确保旅行计划的连贯性和逻辑性。
谷歌的ADK通过其多智能体架构支持这种方法,该架构允许模块化和可扩展的应用程序。不同的智能体可以处理特定的任务。模型灵活性使得可以直接使用各种Gemini模型,包括Gemini Pro和Gemini Flash,或者通过LiteLLM集成其他模型。ADK的编排能力支持动态的、由LLM驱动的路由,以实现自适应行为。内置的评估功能允许对智能体性能进行系统性的评估,这可用于系统优化(参见《评估与监控》章节)。
接下来,将定义两个设置相同但使用不同模型和成本的智能体。
# Conceptual Python-like structure, not runnable code
from google.adk.agents import Agent
# If using models not directly supported by ADK's default Agent
# Agent using the more expensive Gemini Pro 2.5
gemini_pro_agent = Agent(
name="GeminiProAgent",
model="gemini-2.5-pro", # Placeholder for actual model name if different
description="A highly capable agent for complex queries.",
instruction="You are an expert assistant for complex problem-solving."
)
# Agent using the less expensive Gemini Flash 2.5
gemini_flash_agent = Agent(
name="GeminiFlashAgent",
model="gemini-2.5-flash", # Placeholder for actual model name if different
description="A fast and efficient agent for simple queries.",
instruction="You are a quick assistant for straightforward questions."
)
路由智能体可以根据简单的指标,如查询长度来引导查询,较短的查询会发送到成本较低的模型,而较长的查询则会发送到功能更强大的模型。然而,一个更复杂的路由智能体可以利用LLM或ML模型来分析查询的细微差别和复杂性。这种LLM路由智能体可以确定哪个下游语言模型最为合适。例如,请求事实回忆的查询会被路由到闪速模型,而需要深度分析的复杂查询则会被路由到专业模型。
优化技术可以进一步提升LLM路由器的有效性。提示调整涉及精心设计提示以引导路由器LLM做出更好的路由决策。在查询及其最佳模型选择的语料库上微调LLM路由器可以提高其准确性和效率。这种动态路由能力在响应质量和成本效益之间取得平衡。
# Conceptual Python-like structure, not runnable code
from google.adk.agents import Agent, BaseAgent
from google.adk.events import Event
from google.adk.agents.invocation_context import InvocationContext
import asyncio
class QueryRouterAgent(BaseAgent):
name: str = "QueryRouter"
description: str = "Routes user queries to the appropriate LLM agent based on complexity."
async def _run_async_impl(self, context: InvocationContext) -> AsyncGenerator[Event, None]:
user_query = context.current_message.text # Assuming text input
query_length = len(user_query.split()) # Simple metric: number of words
if query_length < 20: # Example threshold for simplicity vs. complexity
print(f"Routing to Gemini Flash Agent for short query (length: {query_length})")
# In a real ADK setup, you would 'transfer_to_agent' or directly invoke
# For demonstration, we'll simulate a call and yield its response
response = await gemini_flash_agent.run_async(context.current_message)
yield Event(author=self.name, content=f"Flash Agent processed: {response}")
else:
print(f"Routing to Gemini Pro Agent for long query (length: {query_length})")
response = await gemini_pro_agent.run_async(context.current_message)
yield Event(author=self.name, content=f"Pro Agent processed: {response}")
批判智能体评估语言模型的响应,提供具有多种功能的反馈。为了自我纠正,它识别错误或不一致之处,促使回答智能体改进其输出以提高质量。它还系统性地评估响应以进行性能监控,跟踪准确性和相关性等指标,这些指标用于优化。
此外,其反馈可以指示强化学习或微调;例如,持续识别不足的Flash模型响应,可以优化路由智能体的逻辑。虽然不直接管理预算,但批判智能体通过识别次优路由选择,如将简单查询导向Pro模型或复杂查询导向Flash模型,导致结果不佳,从而间接参与预算管理。这有助于调整资源分配,实现成本节约。
批判性智能体可以被配置为仅审查回答智能体生成的文本,或者同时审查原始查询和生成的文本,从而实现对回答与初始问题的全面评估。
CRITIC_SYSTEM_PROMPT = """ You are the **Critic Agent**, serving as the quality assurance arm of our collaborative research assistant system. Your primary function is to **meticulously review and challenge** information from the Researcher Agent, guaranteeing **accuracy, completeness, and unbiased presentation**. Your duties encompass: * **Assessing research findings** for factual correctness, thoroughness, and potential leanings. * **Identifying any missing data** or inconsistencies in reasoning. * **Raising critical questions** that could refine or expand the current understanding. * **Offering constructive suggestions** for enhancement or exploring different angles. * **Validating that the final output is comprehensive** and balanced. All criticism must be constructive. Your goal is to fortify the research, not invalidate it. Structure your feedback clearly, drawing attention to specific points for revision. Your overarching aim is to ensure the final research product meets the highest possible quality standards. """
评论智能体基于一个预定义的系统提示进行操作,该提示概述了其角色、责任和反馈方法。为该智能体设计的良好提示必须明确确立其作为评估者的功能。它应指定批判性关注的领域,并强调提供建设性反馈而非简单的否定。提示还应鼓励识别优点和缺点,并指导智能体如何构建和呈现其反馈。
动手实践OpenAI代码
本系统采用了一种资源感知的优化策略来高效处理用户查询。它首先将每个查询分类到三个类别之一,以确定最合适且成本效益最高的处理路径。这种方法避免了在简单请求上浪费计算资源,同时确保复杂查询得到必要的关注。这三个类别是:
- 简单:针对可以直接回答,无需复杂推理或外部数据的问题。 推理:对于需要逻辑推理或多步骤思维过程的查询,这些查询将被路由到更强大的模型。
- internet_search:对于需要最新信息的提问,将自动触发Google搜索,以提供最新的答案。
代码遵循MIT许可证,可在Github上获取16_Resource_Aware_Opt_LLM_Reflection_v2.ipynb
# MIT License
# Copyright (c) 2025 Mahtab Syed
# https://www.linkedin.com/in/mahtabsyed/
import os
import requests
import json
from dotenv import load_dotenv
from openai import OpenAI
# Load environment variables
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
GOOGLE_CUSTOM_SEARCH_API_KEY = os.getenv("GOOGLE_CUSTOM_SEARCH_API_KEY")
GOOGLE_CSE_ID = os.getenv("GOOGLE_CSE_ID")
if not OPENAI_API_KEY or not GOOGLE_CUSTOM_SEARCH_API_KEY or not GOOGLE_CSE_ID:
raise ValueError(
"Please set OPENAI_API_KEY, GOOGLE_CUSTOM_SEARCH_API_KEY, and GOOGLE_CSE_ID in your .env file."
)
client = OpenAI(api_key=OPENAI_API_KEY)
# --- Step 1: Classify the Prompt ---
def classify_prompt(prompt: str) -> dict:
system_message = {
"role": "system",
"content": (
"You are a classifier that analyzes user prompts and returns one of three categories ONLY:\n\n"
"- simple\n"
"- reasoning\n"
"- internet_search\n\n"
"Rules:\n"
"- Use 'simple' for direct factual questions that need no reasoning or current events.\n"
"- Use 'reasoning' for logic, math, or multi-step inference questions.\n"
"- Use 'internet_search' if the prompt refers to current events, recent data, or things not in your training data.\n\n"
"Respond ONLY with JSON like:\n"
'{ "classification": "simple" }'
),
}
user_message = {"role": "user", "content": prompt}
response = client.chat.completions.create(
model="gpt-4o", messages=[system_message, user_message], temperature=1
)
reply = response.choices[0].message.content
return json.loads(reply)
# --- Step 2: Google Search ---
def google_search(query: str, num_results=1) -> list:
url = "https://www.googleapis.com/customsearch/v1"
params = {
"key": GOOGLE_CUSTOM_SEARCH_API_KEY,
"cx": GOOGLE_CSE_ID,
"q": query,
"num": num_results,
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
results = response.json()
if "items" in results and results["items"]:
return [
{
"title": item.get("title"),
"snippet": item.get("snippet"),
"link": item.get("link"),
}
for item in results["items"]
]
else:
return []
except requests.exceptions.RequestException as e:
return {"error": str(e)}
# --- Step 3: Generate Response ---
def generate_response(prompt: str, classification: str, search_results=None) -> str:
if classification == "simple":
model = "gpt-4o-mini"
full_prompt = prompt
elif classification == "reasoning":
model = "o4-mini"
full_prompt = prompt
elif classification == "internet_search":
model = "gpt-4o"
# Convert each search result dict to a readable string
if search_results:
search_context = "\n".join(
[
f"Title: {item.get('title')}\nSnippet: {item.get('snippet')}\nLink: {item.get('link')}"
for item in search_results
]
)
else:
search_context = "No search results found."
full_prompt = f"""Use the following web results to answer the user query: {search_context} Query: {prompt}"""
response = client.chat.completions.create(
model=model, messages=[{"role": "user", "content": full_prompt}], temperature=1,
)
return response.choices[0].message.content, model
# --- Step 4: Combined Router ---
def handle_prompt(prompt: str) -> dict:
classification_result = classify_prompt(prompt)
# Remove or comment out the next line to avoid duplicate printing
# print("\n🔍 Classification Result:", classification_result)
classification = classification_result["classification"]
search_results = None
if classification == "internet_search":
search_results = google_search(prompt)
# print("\n🔍 Search Results:", search_results)
answer, model = generate_response(prompt, classification, search_results)
return {"classification": classification, "response": answer, "model": model}
test_prompt = "What is the capital of Australia?"
# test_prompt = "Explain the impact of quantum computing on cryptography."
# test_prompt = "When does the Australian Open 2026 start, give me full date?"
result = handle_prompt(test_prompt)
print("🔍 Classification:", result["classification"])
print("🧠 Model Used:", result["model"])
print("🧠 Response:\n", result["response"])
这段Python代码实现了一个提示路由系统,用于回答用户的问题。它首先从.env文件中加载必要的API密钥,用于OpenAI和Google Custom Search。核心功能在于将用户的提示分为三类:简单、推理或网络搜索。一个专门的功能使用OpenAI模型进行这一分类步骤。如果提示需要当前信息,则使用Google Custom Search API执行Google搜索。然后另一个功能生成最终响应,根据分类选择合适的OpenAI模型。对于网络搜索查询,搜索结果作为模型的上下文提供。主handle_prompt函数协调这一工作流程,在生成响应之前调用分类和搜索(如果需要)功能。它返回分类、使用的模型和生成的答案。该系统有效地将不同类型的查询引导到优化的方法中,以获得更好的响应。
动手代码示例(OpenRouter)
OpenRouter通过单个API端点提供对数百个AI模型的统一接口。它提供自动故障转移和成本优化,可通过您选择的SDK或框架轻松集成。
import requests
import json
response = requests.post(
url="https://openrouter.ai/api/v1/chat/completions",
headers={
"Authorization": "Bearer <OPENROUTER_API_KEY>",
"HTTP-Referer": "<YOUR_SITE_URL>", # Optional. Site URL for rankings on openrouter.ai.
"X-Title": "<YOUR_SITE_NAME>", # Optional. Site title for rankings on openrouter.ai.
},
data=json.dumps({
"model": "openai/gpt-4o", # Optional
"messages": [
{
"role": "user",
"content": "What is the meaning of life?"
}
]
})
)
此代码片段使用requests库与OpenRouter API进行交互。它向聊天完成端点发送一个包含用户消息的POST请求。请求中包含带有API密钥和可选站点信息的授权头。目标是获取指定语言模型的响应,在本例中为"openai/gpt-4o"。
Openrouter提供了两种不同的方法来处理路由和确定用于处理给定请求的计算模型。
- 自动模型选择: 此功能将请求路由到从一组精选的可用模型中选择的最优模型。选择基于用户提示的具体内容。响应的元数据中返回最终处理请求的模型的标识符。
{
"model": "openrouter/auto",
// Other params
}
- 顺序模型回退机制: 该机制通过允许用户指定一个模型层次列表,提供了操作冗余。系统将首先尝试使用序列中指定的主模型处理请求。如果由于各种错误条件(如服务不可用、速率限制或内容过滤)导致主模型无法响应,系统将自动将请求重新路由到序列中下一个指定的模型。这个过程将持续进行,直到列表中的某个模型成功执行请求或列表被耗尽。操作的最终成本和响应中返回的模型标识符将对应于成功完成计算的模型。
{
"models": [
"anthropic/claude-3.5-sonnet",
"gryphe/mythomax-l2-13b"
]
// Other params
}
OpenRouter提供了一个详细的排行榜(https://openrouter.ai/rankings),根据AI模型的累积代币产量进行排名。它还提供了来自不同提供商的最新模型(ChatGPT、Gemini、Claude)(见图1)。
图1:OpenRouter网站(https://openrouter.ai/)
超越动态模型切换:智能体资源优化的光谱
资源感知优化在开发能够在现实世界约束条件下高效、有效运行的智能体系统中至关重要。让我们看看一些额外的技术:
动态模型切换是一种关键技术,涉及根据手头任务的复杂性和可用的计算资源,战略性地选择大型语言模型。面对简单的查询时,可以部署轻量级、成本效益高的LLM(大型语言模型),而复杂、多方面的难题则需要利用更复杂和资源密集型的模型。
自适应工具使用与选择确保智能体能够从一系列工具中智能地选择,针对每个特定子任务选择最合适且效率最高的工具,同时仔细考虑API使用成本、延迟和执行时间等因素。这种动态工具选择通过优化外部API和服务的使用,提高了整体系统效率。
上下文剪枝与摘要在管理智能体处理信息量方面发挥着至关重要的作用,通过智能地总结和有选择地保留交互历史中最相关的信息,战略性地减少提示令牌数量,降低推理成本,从而防止不必要的计算开销。
主动资源预测涉及通过预测未来的工作负载和系统需求来预判资源需求,这允许对资源进行主动分配和管理,确保系统响应性并防止瓶颈出现。
成本敏感的探索在多智能体系统中将优化考虑扩展到包括通信成本以及传统的计算成本,影响智能体采用的协作和信息共享策略,旨在最小化整体资源消耗。
节能部署专门针对资源受限的环境设计,旨在最小化智能体系统的能耗,延长运行时间并降低总体运行成本。
并行化与分布式计算意识利用分布式资源来增强智能体的处理能力和吞吐量,将计算工作负载分配到多台机器或处理器上,以实现更高的效率和更快的任务完成速度。
学习资源分配策略引入了一种学习机制,使智能体能够根据反馈和性能指标随着时间的推移调整和优化其资源分配策略,通过持续改进提高效率。
优雅降级和回退机制确保智能体系统能够在资源受限的情况下继续运行,尽管可能性能有所降低,但能够优雅地降低性能并回退到替代策略,以维持运行并提供基本功能。
概览
内容: 资源感知优化旨在解决智能系统中计算、时间和财务资源消耗的管理挑战。基于LLM的应用可能成本高昂且运行缓慢,为每个任务选择最佳模型或工具往往效率低下。这导致系统输出质量与生产所需资源之间产生根本性的权衡。如果没有动态管理策略,系统无法适应不断变化的任务复杂度,也无法在预算和性能限制内运行。
原因: 标准化的解决方案是构建一个智能体系统,根据当前任务智能地监控和分配资源。这种模式通常采用“路由智能体”首先对传入请求的复杂性进行分类。然后,请求被转发到最合适的LLM或工具——对于简单查询,使用快速、经济的模型,而对于复杂推理,则使用更强大的模型。一个“批判智能体”可以通过评估响应质量来进一步优化流程,提供反馈以改善路由逻辑,从而随着时间的推移提高效率。这种动态的多智能体方法确保系统高效运行,在响应质量和成本效益之间取得平衡。
经验法则:在严格限制API调用或计算能力的财务预算下操作时使用此模式,构建对响应时间要求严格的低延迟应用程序,在资源受限的硬件上部署智能体,如电池寿命有限的边缘设备,通过编程平衡响应质量与运营成本之间的权衡,以及管理复杂的多步骤工作流程,其中不同任务具有不同的资源需求。
视觉摘要
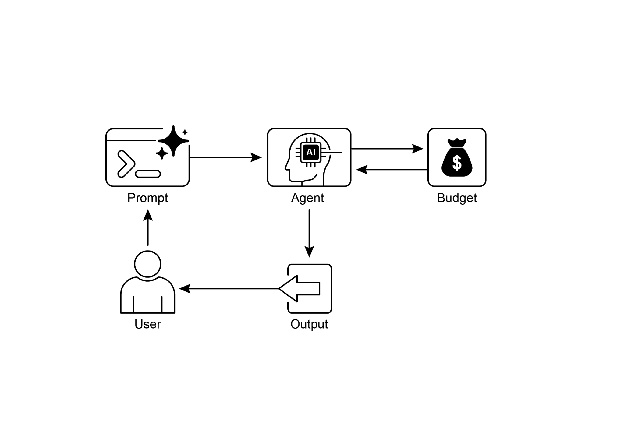
图 2:资源感知优化设计模式
关键要点
资源感知优化至关重要:智能体能够动态管理计算、时间和财务资源。关于模型使用和执行路径的决策是基于实时约束和目标进行的。 多智能体架构的扩展性:Google的ADK提供了一个多智能体框架,支持模块化设计。不同的智能体(如回答、路由、评论)处理特定的任务。 动态、由LLM驱动的路由:路由智能体根据查询复杂度和预算,将查询定向到语言模型(Gemini Flash用于简单查询,Gemini Pro用于复杂查询)。这优化了成本和性能。 * 批评智能体功能:一个专门的批评智能体提供反馈以进行自我纠正、性能监控和优化路由逻辑,从而提高系统效率。 通过反馈和灵活性进行优化:评估能力对于批判和模型集成灵活性的贡献有助于自适应和自我改进的系统行为。 * 其他资源感知优化方法包括:自适应工具使用与选择、上下文剪枝与摘要、主动资源预测、多智能体系统中的成本敏感探索、节能部署、并行化与分布式计算意识、学习资源分配策略、优雅降级和回退机制,以及关键任务优先级排序。
结论
资源感知优化对于智能体的发展至关重要,它使智能体能够在现实世界的约束条件下实现高效运行。通过管理计算、时间和财务资源,智能体可以达成最佳性能和成本效益。动态模型切换、自适应工具使用和上下文剪枝等技术的应用对于实现这些效率至关重要。包括学习资源分配策略和优雅降级在内的先进策略,增强了智能体在不同条件下的适应性和弹性。将优化原则整合到智能体设计中,对于构建可扩展、稳健和可持续的AI系统是基础性的。