第21章:探索与发现
本章探讨了智能体在运营环境中主动寻求新信息、发现新可能性以及识别未知未知模式的策略。探索与发现不同于在预定义解决方案空间内的反应性行为或优化。相反,它们侧重于智能体主动进入未知领域,尝试新的方法,并产生新的知识或理解。这种模式对于在开放性、复杂性或快速发展的领域中运行的智能体至关重要,在这些领域中,静态知识或预先编程的解决方案是不够的。它强调了智能体扩展其理解和能力的能力。
实际应用与用例
智能体具备智能优先级排序和探索的能力,这使得它们在各个领域得到广泛应用。通过自主评估和排序潜在的行动,这些智能体能够在复杂环境中导航,揭示隐藏的洞察力,并推动创新。这种优先级探索的能力使它们能够优化流程,发现新知识,并生成内容。
示例:
- 科学研究自动化: 智能体负责设计并运行实验,分析结果,并制定新的假设,以发现新型材料、药物候选物或科学原理。
- 游戏玩法与策略生成: 智能体探索游戏状态,发现涌现的策略或识别游戏环境中的弱点(例如,AlphaGo)。
- 市场调研和趋势发现: 智能体扫描非结构化数据(社交媒体、新闻、报告)以识别趋势、消费者行为或市场机会。
- 安全漏洞发现: 智能体探测系统或代码库以寻找安全漏洞或攻击向量。
- 创意内容生成: 智能体通过探索风格、主题或数据的组合来生成艺术作品、音乐作品或文学作品。
- 个性化教育和培训: 智能导师根据学生的进度、学习风格和需要改进的领域,优先考虑学习路径和内容交付。
谷歌联合科学家
人工智能协同科学家是由谷歌研究开发的一种人工智能系统,旨在作为计算科学合作者。它协助人类科学家在假设生成、提案精炼和实验设计等研究方面提供帮助。该系统运行在Gemini LLM上。
人工智能协同科学家的发展旨在解决科学研究中的挑战。这些挑战包括处理大量信息、生成可检验的假设以及管理实验规划。人工智能协同科学家通过执行涉及大规模信息处理和综合的任务来支持研究人员,这些任务有可能揭示数据中的关系。其目的是通过处理早期研究中的计算密集型方面来增强人类认知过程。
系统架构与方法论: AI协同科学家的架构基于多智能体框架,旨在模拟协作和迭代过程。该设计集成了具有特定角色的专业AI智能体,每个智能体都在贡献研究目标方面发挥作用。一个管理智能体负责管理和协调这些个体智能体在异步任务执行框架中的活动,该框架允许灵活扩展计算资源。
核心智能体及其功能包括(见图1):
- 生成智能体:通过文献探索和模拟科学辩论产生初始假设,从而启动整个过程。
- 反射智能体:充当同行评审员,对生成的假设的正确性、新颖性和质量进行批判性评估。
- 排名智能体:采用基于Elo的锦标赛来比较、排名和优先排序假设,通过模拟科学辩论来实现。
- 进化智能体:通过简化概念、综合思想和探索非常规推理,持续优化排名靠前的假设。
- 邻近智能体:计算邻近图以聚类相似想法并协助探索假设景观。
- 元审查智能体:综合所有评论和辩论的见解,以识别共同模式并提供反馈,使系统能够持续改进。
该系统的运行基础依赖于Gemini,它提供了语言理解、推理和生成能力。系统集成了“测试时计算扩展”机制,该机制通过迭代推理和增强输出分配更多的计算资源。系统从多种来源处理和综合信息,包括学术文献、基于网络的数据和数据库。
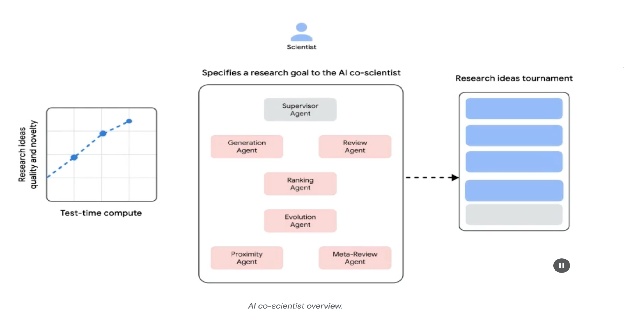 Fig. 1: (Courtesy of the Authors) AI Co-Scientist: Ideation to Validation
Fig. 1: (Courtesy of the Authors) AI Co-Scientist: Ideation to Validation
该系统遵循一种迭代的“生成、辩论和进化”方法,类似于科学研究方法。在人类科学家输入科学问题后,系统进入一个自我改进的循环,包括假设生成、评估和细化。假设将接受系统性的评估,包括智能体之间的内部评估以及基于锦标赛的排名机制。
验证与结果: AI协同科学家的实用性已在多个验证研究中得到证明,尤其是在生物医药领域,通过自动化基准测试、专家评审和端到端湿实验室实验来评估其性能。
自动化与专家评估: 在具有挑战性的GPQA基准测试中,该系统的内部Elo评分与其结果的准确性一致,在困难的“钻石集”上实现了78.4%的top-1准确率。对超过200个研究目标的跨分析表明,测试时计算规模的扩大始终能够通过Elo评分来衡量假设的质量。在精心挑选的15个具有挑战性的问题上,该人工智能协同科学家优于其他最先进的AI模型以及由人类专家提供的“最佳猜测”解决方案。在小规模评估中,生物医学专家认为该协同科学家的输出比其他基线模型更具创新性和影响力。该系统提出的药物再利用方案,以NIH特定目标页面格式呈现,也由六位专家肿瘤学家组成的评审团判定为高质量。
端到端实验验证:
药物再利用:针对急性髓系白血病(AML),该系统提出了新的药物候选者。其中一些,如KIRA6,是完全新颖的建议,在AML中应用之前没有任何临床前证据。随后的体外实验证实,KIRA6和其他建议的药物在多个AML细胞系中,在临床相关浓度下抑制了肿瘤细胞的存活。
新型靶点发现:该系统识别出了针对肝纤维化的新型表观遗传学靶点。使用人肝类器官进行的实验室实验验证了这些发现,表明针对所建议的表观遗传学修饰剂的药物具有显著的抗纤维化活性。其中一种已识别的药物已被FDA批准用于另一种疾病,这为重新利用提供了机会。
抗菌耐药性:该AI智能体独立地回顾了未发表的实验发现。其任务是解释为什么某些移动遗传元件(cf-PICIs)在许多细菌物种中都被发现。在两天内,该系统的顶级假设是cf-PICIs与多种噬菌体尾部相互作用,以扩大其宿主范围。这反映了独立研究小组在经过十多年的研究后所取得的创新性、经实验验证的发现。
增强与局限性: AI协同科学家的设计理念强调的是增强而非完全自动化人类研究。研究人员通过与系统进行自然语言交互,提供反馈,贡献自己的想法,并在“科学家在环”的协作范式下指导AI的探索过程。然而,该系统存在一些局限性。它的知识受限于其对开放获取文献的依赖,可能会错过付费墙背后的关键先前工作。此外,它对负面实验结果的访问有限,这些结果很少被发表,但对于经验丰富的科学家来说至关重要。此外,该系统继承了底层LLM的局限性,包括可能的事实不准确或“幻觉”的可能性。
安全:安全是一个至关重要的考虑因素,该系统集成了多重安全防护措施。所有研究目标在输入时都会进行安全审查,生成的假设也会进行检查,以防止系统被用于不安全或不道德的研究。通过使用1,200个对抗性研究目标进行初步安全评估,发现该系统能够稳健地拒绝危险输入。为确保负责任地开发,该系统将通过可信测试者计划向更多科学家开放,以收集真实世界的反馈。
动手代码示例
让我们来看一个关于探索与发现中智能体AI的具体实例:Agent Laboratory,这是一个由Samuel Schmidgall在MIT许可证下开发的项目。
“智能体实验室”是一个自主研究工作流程框架,旨在增强人类科学努力,而非取代它们。该系统利用专门的LLM(大型语言模型)来自动化科学研究过程的各个阶段,从而使得人类研究人员能够将更多的认知资源投入到概念化和批判性分析中。
该框架集成了“AgentRxiv”,一个用于自主研究智能体的去中心化存储库。AgentRxiv促进了研究成果的存档、检索和开发。
智能体实验室通过不同的阶段引导研究过程:
- 文献综述: 在这个初始阶段,由专门的大型语言模型(LLM)驱动的智能体负责自主收集和批判性分析相关学术文献。这包括利用外部数据库(如arXiv)来识别、综合和分类相关研究,从而为后续阶段建立一个全面的知识库。
- 实验阶段: 这一阶段包括实验设计的协同制定、数据准备、实验执行和结果分析。智能体利用集成的工具,如Python进行代码生成和执行,以及Hugging Face进行模型访问,以进行自动化实验。该系统旨在实现迭代优化,智能体可以根据实时结果调整和优化实验流程。
- 报告撰写: 在最终阶段,系统自动生成全面的研究报告。这包括将实验阶段的发现与文献综述的见解相结合,根据学术规范结构化文档,并整合外部工具如LaTeX进行专业格式化和图表生成。
- 知识共享:AgentRxiv是一个平台,它使自主研究智能体能够分享、访问和协作推进科学发现。该平台允许智能体在以往发现的基础上进行构建,促进累积性研究进展。
智能体实验室的模块化架构确保了计算灵活性。目标是通过对任务进行自动化以提高研究效率,同时保持人类研究者的角色。
代码分析: 虽然全面的代码分析超出了本书的范围,但我希望为您提供一些关键见解,并鼓励您自己深入研究代码。
判断:为了模拟人类的评估过程,系统采用了一种三重智能体判断机制来评估输出。这涉及到部署三个不同的自主智能体,每个智能体都配置为从特定角度评估生产内容,从而共同模拟人类判断的细微和多维度特性。这种方法允许进行更稳健和全面的评估,超越了单一指标,捕捉更丰富的定性评估。
class ReviewersAgent:
def __init__(self, model="gpt-4o-mini", notes=None, openai_api_key=None):
if notes is None:
self.notes = []
else:
self.notes = notes
self.model = model
self.openai_api_key = openai_api_key
def inference(self, plan, report):
reviewer_1 = "You are a harsh but fair reviewer and expect good experiments that lead to insights for the research topic."
review_1 = get_score(outlined_plan=plan, latex=report, reward_model_llm=self.model, reviewer_type=reviewer_1, openai_api_key=self.openai_api_key)
reviewer_2 = "You are a harsh and critical but fair reviewer who is looking for an idea that would be impactful in the field."
review_2 = get_score(outlined_plan=plan, latex=report, reward_model_llm=self.model, reviewer_type=reviewer_2, openai_api_key=self.openai_api_key)
reviewer_3 = "You are a harsh but fair open-minded reviewer that is looking for novel ideas that have not been proposed before."
review_3 = get_score(outlined_plan=plan, latex=report, reward_model_llm=self.model, reviewer_type=reviewer_3, openai_api_key=self.openai_api_key)
return f"Reviewer #1:\n{review_1}, \nReviewer #2:\n{review_2}, \nReviewer #3:\n{review_3}"
判断智能体被设计成使用特定的提示,该提示紧密模仿了人类审阅者通常采用的认知框架和评估标准。这个提示指导智能体通过类似于人类专家的方式分析输出,考虑因素包括相关性、连贯性、事实准确性以及整体质量。通过将这些提示设计成与人类审阅协议相呼应,系统旨在实现接近人类判断能力的评估复杂性。
def get_score(outlined_plan, latex, reward_model_llm, reviewer_type=None, attempts=3, openai_api_key=None):
e = str()
for _attempt in range(attempts):
try:
template_instructions = """Respond in the following format:
THOUGHT:
<THOUGHT>
REVIEW JSON:
<JSON>
In <THOUGHT>, first briefly discuss your intuitions and reasoning for the evaluation. Detail your high-level arguments, necessary choices and desired outcomes of the review. Do not make generic comments here, but be specific to your current paper. Treat this as the note-taking phase of your review.
In <JSON>, provide the review in JSON format with the following fields in the order:
- "Summary": A summary of the paper content and its contributions.
- "Strengths": A list of strengths of the paper.
- "Weaknesses": A list of weaknesses of the paper.
- "Originality": A rating from 1 to 4 (low, medium, high, very high).
- "Quality": A rating from 1 to 4 (low, medium, high, very high).
- "Clarity": A rating from 1 to 4 (low, medium, high, very high).
- "Significance": A rating from 1 to 4 (low, medium, high, very high).
- "Questions": A set of clarifying questions to be answered by the paper authors.
- "Limitations": A set of limitations and potential negative societal impacts of the work.
- "Ethical Concerns": A boolean value indicating whether there are ethical concerns.
- "Soundness": A rating from 1 to 4 (poor, fair, good, excellent).
- "Presentation": A rating from 1 to 4 (poor, fair, good, excellent).
- "Contribution": A rating from 1 to 4 (poor, fair, good, excellent).
- "Overall": A rating from 1 to 10 (very strong reject to award quality).
- "Confidence": A rating from 1 to 5 (low, medium, high, very high, absolute).
- "Decision": A decision that has to be one of the following: Accept, Reject.
For the "Decision" field, don't use Weak Accept, Borderline Accept, Borderline Reject, or Strong Reject. Instead, only use Accept or Reject.
This JSON will be automatically parsed, so ensure the format is precise.
"""
在这个多智能体系统中,研究过程围绕专业角色进行结构化,类似于典型的学术等级制度,以简化工作流程并优化输出。
教授智能体: 教授智能体作为主要的研究总监,负责制定研究议程、定义研究问题和将任务委派给其他智能体。该智能体设定战略方向,并确保与项目目标保持一致。
class ProfessorAgent(BaseAgent):
def __init__(self, model="gpt4omini", notes=None, max_steps=100, openai_api_key=None):
super().__init__(model, notes, max_steps, openai_api_key)
self.phases = ["report writing"]
def generate_readme(self):
sys_prompt = f"""You are {self.role_description()} \n Here is the written paper \n{self.report}. Task instructions: Your goal is to integrate all of the knowledge, code, reports, and notes provided to you and generate a readme.md for a github repository."""
history_str = "\n".join([_[1] for _ in self.history])
prompt = (
f"""History: {history_str}\n{'~' * 10}\n"""
f"Please produce the readme below in markdown:\n"
)
model_resp = query_model(model_str=self.model, system_prompt=sys_prompt, prompt=prompt, openai_api_key=self.openai_api_key)
return model_resp.replace("```markdown", "")
博士后智能体: 博士后智能体的职责是执行研究工作。这包括进行文献综述、设计和实施实验,以及生成研究成果,如论文。重要的是,博士后智能体具备编写和执行代码的能力,这使得实验方案的实际实施和数据分析成为可能。该智能体是研究成果的主要生产者。
class PostdocAgent(BaseAgent):
def __init__(self, model="gpt4omini", notes=None, max_steps=100, openai_api_key=None):
super().__init__(model, notes, max_steps, openai_api_key)
self.phases = ["plan formulation", "results interpretation"]
def context(self, phase):
sr_str = ""
if self.second_round:
sr_str = (
"The following are results from the previous experiments\n",
f"Previous Experiment code: {self.prev_results_code}\n",
f"Previous Results: {self.prev_exp_results}\n",
f"Previous Interpretation of results: {self.prev_interpretation}\n",
f"Previous Report: {self.prev_report}\n",
f"{self.reviewer_response}\n\n\n"
)
if phase == "plan formulation":
return (
sr_str,
f"Current Literature Review: {self.lit_review_sum}",
)
elif phase == "results interpretation":
return (
sr_str,
f"Current Literature Review: {self.lit_review_sum}\n",
f"Current Plan: {self.plan}\n",
f"Current Dataset code: {self.dataset_code}\n",
f"Current Experiment code: {self.results_code}\n",
f"Current Results: {self.exp_results}"
)
return ""
审稿智能体: 审稿智能体对博士后智能体输出的研究成果进行关键评估,评估论文和实验结果的质量、有效性和科学严谨性。这一评估阶段模拟学术环境中的同行评审过程,以确保在最终定稿前研究成果达到高标准。
机器学习工程智能体:机器学习工程智能体充当机器学习工程师的角色,与博士生进行对话式协作以开发代码。其核心功能是生成简单的代码用于数据预处理,整合从提供的文献综述和实验方案中得出的见解。这确保了数据被适当地格式化和准备,以便进行指定的实验。
"You are a machine learning engineer being directed by a PhD student who will help you write the code, and you can interact with them through dialogue.
Your goal is to produce code that prepares the data for the provided experiment. You should aim for simple code to prepare the data, not complex code. You should integrate the provided literature review and the plan and come up with code to prepare data for this experiment."
SWEngineerAgents(软件工程智能体): 软件工程智能体指导机器学习工程师智能体。它们的主要目的是协助机器学习工程师智能体为特定实验创建简单的数据准备代码。软件工程智能体整合提供的文献综述和实验计划,确保生成的代码简单易懂,并与研究目标直接相关。
"You are a software engineer directing a machine learning engineer, where the machine learning engineer will be writing the code, and you can interact with them through dialogue.
Your goal is to help the ML engineer produce code that prepares the data for the provided experiment. You should aim for very simple code to prepare the data, not complex code. You should integrate the provided literature review and the plan and come up with code to prepare data for this experiment."
总的来说,“智能体实验室”代表了一种用于自主科学研究的复杂框架。它旨在通过自动化关键研究阶段并促进由人工智能驱动的知识生成协作,来增强人类的研究能力。该系统旨在通过管理常规任务的同时保持人类监督,以提高研究效率。
概览
内容: 智能体通常在预定义的知识范围内运行,这限制了它们应对新情况或开放式问题的能力。在复杂和动态的环境中,这种静态、预编程的信息对于真正的创新或发现是不够的。基本挑战在于使智能体能够超越简单的优化,积极寻求新信息并识别“未知未知”。这需要从纯粹的反应性行为向主动的、具有智能体探索性的行为转变,以扩展系统的理解和能力。
原因: 标准化的解决方案是构建专门为自主探索和发现而设计的智能体AI系统。这些系统通常采用多智能体框架,其中专门的LLM协同工作,模拟科学方法等过程。例如,不同的智能体可以负责生成假设、批判性地审查它们,并发展最有希望的概念。这种结构化和协作的方法使系统能够智能地导航庞大的信息领域,设计并执行实验,并产生真正的新知识。通过自动化探索中的劳动密集型方面,这些系统增强了人类智慧,并显著加快了发现的步伐。
经验法则: 在操作开放性、复杂或快速演变的领域时,当解决方案空间尚未完全定义时,请使用探索与发现模式。该模式非常适合需要生成新颖假设、策略或洞察的任务,例如在科学研究、市场分析和创意内容生成中。当目标是为了揭示“未知之未知”而非仅仅优化已知过程时,此模式至关重要。
视觉摘要
图2:探索与发现设计模式
关键要点
人工智能中的探索与发现使智能体能够积极寻求新的信息和可能性,这对于在复杂和不断变化的环境中导航至关重要。类似于谷歌协同科学家这样的系统展示了智能体如何自主生成假设和设计实验,从而补充人类科学研究。 多智能体框架,以Agent Laboratory的专业角色为例,通过自动化文献综述、实验和报告撰写,提升了研究效率。 最终,这些智能体的目标是通过对计算密集型任务的管理来提升人类的创造力和解决问题的能力,从而加速创新和发现。
结论
总结来说,探索与发现模式是真正智能体系统的核心本质,它定义了系统超越被动遵循指令的能力,能够主动探索其环境。这种天生的智能体驱动力赋予人工智能在复杂领域自主操作的能力,而不仅仅是执行任务,还能够独立设定子目标以发现新信息。这种高级的智能体行为通过多智能体框架得到最强大的实现,其中每个智能体在更大的协作过程中扮演着特定的、主动的角色。例如,谷歌的协同科学家系统就是一个高度智能体的系统,其特征在于智能体能够自主生成、辩论和演进科学假设。
像智能体实验室这样的框架通过创建一个模仿人类研究团队的智能体层级结构,进一步结构化这一过程,使系统能够自我管理整个发现生命周期。这一模式的核心在于协调涌现的智能体行为,允许系统在最小的人为干预下追求长期、开放的目标。这提升了人机协作,将AI定位为真正的智能体合作者,负责自主执行探索性任务。通过将这种主动的发现工作委托给智能体系统,人类智慧得到了显著增强,加速了创新。这种强大的智能体能力的发展也需要对安全和伦理监管的强烈承诺。最终,这一模式为创建真正的智能体AI提供了蓝图,将计算工具转变为追求知识中的独立、目标导向的合作伙伴。