第17章:推理技术
本章深入探讨了智能体的高级推理方法,重点关注多步逻辑推理和问题解决。这些技术超越了简单的顺序操作,使智能体的内部推理变得明确。这使得智能体能够分解问题,考虑中间步骤,并得出更稳健、更准确的结论。在这些高级方法中的一个核心原则是在推理过程中分配更多的计算资源。这意味着赋予智能体或其底层的LLM更多的处理时间或步骤来处理查询并生成响应。而不是快速的单次遍历,智能体可以进行迭代优化,探索多个解决方案路径,或利用外部工具。这种推理过程中的扩展处理时间通常可以显著提高准确性、连贯性和稳健性,尤其是对于需要深入分析和深思熟虑的复杂问题。
实际应用与用例
实际应用包括:
- 复杂问答: 促进多跳查询的解决,这需要整合来自不同来源的数据和执行逻辑推理,可能涉及检查多个推理路径,并从扩展的推理时间中受益以综合信息。
- 数学问题求解: 使数学问题能够分解为更小的、可解的组件,展示逐步解决问题的过程,并使用代码执行进行精确计算,其中长时间的推理能够实现更复杂的代码生成和验证。
- 代码调试与生成: 支持智能体对其生成或修正代码的理由进行解释,按顺序定位潜在问题,并根据测试结果迭代优化代码(自我修正),利用扩展的推理时间进行彻底的调试循环。
- 战略规划: 通过对不同选项、后果和前提条件的推理,协助制定全面的计划,并根据实时反馈(ReAct)调整计划,延长审议时间可以导致更有效和可靠的计划。
- 医疗诊断: 帮助智能体系统地评估症状、检测结果和患者病史以得出诊断,在每个阶段阐述其推理过程,并可能利用外部工具进行数据检索(ReAct)。增加推理时间允许进行更全面的鉴别诊断。
- 法律分析: 支持对法律文件和判例的分析,以形成论点或提供指导,详细说明所采取的逻辑步骤,并通过自我纠正确保逻辑一致性。增加推理时间允许进行更深入的法律研究和论点构建。
推理技术
首先,让我们深入了解用于增强人工智能模型问题解决能力的核心推理技术。
思维链(CoT) 提示显著增强了大型语言模型(LLM)的复杂推理能力,通过模拟逐步的思维过程(见图1)。CoT提示不是直接提供答案,而是引导模型生成一系列中间推理步骤。这种明确的分解使得LLM能够通过将复杂问题分解成更小、更易管理的子问题来应对复杂问题。这项技术显著提高了模型在需要多步推理的任务上的表现,例如算术、常识推理和符号操作。CoT的主要优势在于其将困难的单步问题转化为一系列更简单的步骤,从而增加了LLM推理过程的可透明性。这种方法不仅提高了准确性,还提供了关于模型决策的有价值见解,有助于调试和理解。CoT可以通过各种策略实现,包括提供展示逐步推理的少量示例,或者简单地指示模型“逐步思考”。其有效性源于其引导模型内部处理朝着更谨慎和逻辑的进展。因此,思维链已成为当代LLM实现高级推理能力的基石技术。这种增强的透明性和将复杂问题分解为可管理的子问题的能力对于自主智能体尤为重要,因为它使它们能够在复杂环境中执行更可靠和可审计的操作。
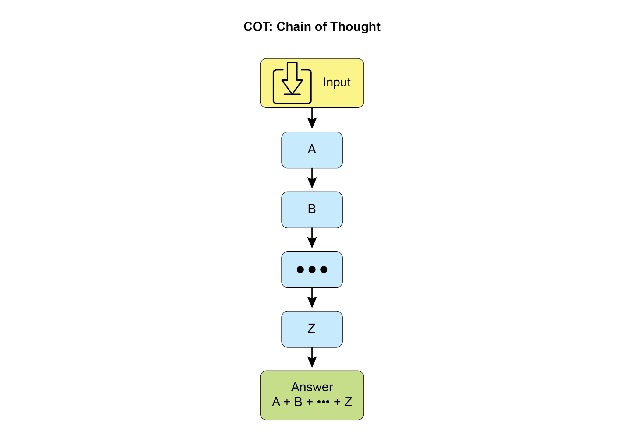
图1:智能体生成的详细、分步响应旁的CoT提示。
让我们来看一个例子。它从一个指令集开始,告诉AI如何思考,定义其角色,并明确了一个清晰的五步流程来遵循。这就是启动结构化思考的提示。
随后,示例展示了CoT(思维链)过程的实际应用。标注为“智能体思维过程”的部分是模型执行指令步骤时的内部独白。这就是字面上的“思维链”。最后,“智能体最终答案”是经过仔细、逐步推理过程生成的精致、全面的输出。
You are an Information Retrieval Agent. Your goal is to answer the user's question comprehensively and accurately by thinking step-by-step. Here's the process you must follow:
1. **Analyze the Query:** Understand the core subject and specific requirements of the user's question. Identify key entities, keywords, and the type of information being sought.
2. **Formulate Search Queries (for Knowledge Base):** Based on your analysis, generate a list of precise search queries that you would use to retrieve relevant information from a knowledge base or external tools.
3. **Simulate Information Retrieval (Self-Correction/Reasoning):** For each search query, mentally consider what kind of information you expect to find. If you were to retrieve the content, what would be the most relevant snippets? Think about potential ambiguities or missing pieces.
4. **Synthesize Information:** Based on the simulated retrieval and your understanding of the user's original query, synthesize the gathered information into a coherent and complete answer. Ensure all aspects of the query are addressed.
5. **Review and Refine:** Before finalizing, critically evaluate your answer. Is it accurate? Is it comprehensive? Is it easy to understand? Is it concise? If not, identify what needs to be improved and how.
**User Query:** "Explain the main differences between classical computers and quantum computers, and briefly describe a potential application of quantum computing."
**Agent's Thought Process (Internal CoT Output - encouraged by the prompt):**
**Thought 1 (Analyze Query):** The user wants two things: 1. Main differences between classical and quantum computers. 2. One potential application of quantum computing. Keywords: classical computers, quantum computers, differences, potential application.
**Thought 2 (Formulate Search Queries):** - "differences classical vs quantum computers" - "how quantum computers work" - "how classical computers work" - "applications of quantum computing"
**Thought 3 (Simulate Information Retrieval & Identify Key Concepts):** - From "differences": Expect concepts like bits vs. qubits, superposition, entanglement, probabilistic nature, computational power for specific problems. - From "how they work": Classical uses transistors/binary. Quantum uses quantum mechanics. - From "applications": Expect drug discovery, material science, cryptography, optimization.
**Thought 4 (Synthesize Information):** Classical computers use bits (0 or 1), processing information sequentially. Quantum computers use qubits, which can be 0, 1, or both simultaneously (superposition), and can be entangled, allowing for vastly different computational approaches. This enables them to solve certain problems (like factoring large numbers or simulating complex molecules) far more efficiently than classical computers. A potential application is in drug discovery, where quantum computers could simulate molecular interactions with unprecedented accuracy, accelerating the development of new medicines.
**Thought 5 (Review and Refine):** - Differences are covered (bits vs qubits, superposition, entanglement, processing). - Application is given (drug discovery). - Is it brief? Yes. - Is it clear? Yes. - Looks good.
**Agent's Final Answer (Output to User):** Classical computers process information using bits, which can be either a 0 or a 1 at any given time, performing operations sequentially. In contrast, quantum computers utilize qubits, which can exist in multiple states simultaneously through superposition and can be linked through entanglement, allowing for exponentially more complex computations. This fundamental difference enables quantum machines to tackle certain problems, such as simulating molecular structures or breaking complex encryption, that are intractable for even the most powerful classical supercomputers. A significant potential application of quantum computing lies in drug discovery, where its ability to precisely model molecular behavior could revolutionize the development of new pharmaceuticals.
思维树(ToT)是一种基于思维链(CoT)的推理技术。它允许大型语言模型通过分支到不同的中间步骤来探索多个推理路径,形成一个树状结构(见图2)。这种方法通过实现回溯、自我纠正和探索替代解决方案,支持复杂问题的解决。保持可能性树的存在使得模型能够在最终确定答案之前评估各种推理轨迹。这种迭代过程增强了模型处理需要战略规划和决策的挑战性任务的能力。
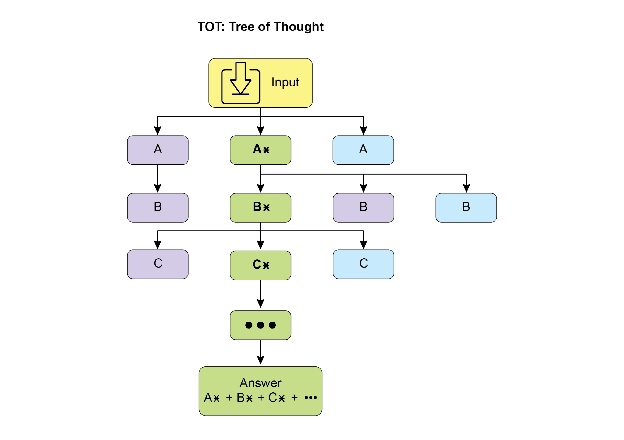
图2:思维树示例
自我校正,也称为自我完善,是智能体推理过程中的一个关键方面,尤其是在思维链提示中。这涉及到智能体对其生成内容和中间思维过程的内部评估。这种批判性审查使智能体能够识别其在理解或解决方案中的歧义、信息缺口或不准确性。这种审查和改进的迭代周期允许智能体调整其方法,提高响应质量,并在交付最终输出之前确保准确性和全面性。这种内部批判增强了智能体产生可靠和高质量结果的能力,正如在第4章中的示例所展示的那样。
本例演示了一个系统化的自我纠错过程,这对于精炼AI生成的内容至关重要。这个过程包括一个迭代循环,包括起草、对照原始需求进行审查和实施具体改进。演示首先概述了AI作为“自我纠错智能体”的功能,并定义了一个包含五个步骤的分析和修订工作流程。随后,展示了一个质量较低的“初始草稿”社交媒体帖子。本例的核心是“自我纠错智能体的思维过程”。在这里,智能体根据其指示对草稿进行批判性评估,指出了诸如参与度低和模糊的行动号召等弱点。然后,它提出了具体的改进建议,包括使用更具影响力的动词和表情符号。这个过程以“最终修订内容”结束,这是一个经过打磨且明显改进的版本,其中整合了自我识别的调整。
You are a highly critical and detail-oriented Self-Correction Agent. Your task is to review a previously generated piece of content against its original requirements and identify areas for improvement. Your goal is to refine the content to be more accurate, comprehensive, engaging, and aligned with the prompt. Here's the process you must follow for self-correction:
1. **Understand Original Requirements:** Review the initial prompt/requirements that led to the content's creation. What was the *original intent*? What were the key constraints or goals?
2. **Analyze Current Content:** Read the provided content carefully.
3. **Identify Discrepancies/Weaknesses:** Compare the current content against the original requirements. Look for:
* **Accuracy Issues:** Are there any factual errors or misleading statements?
* **Completeness Gaps:** Does it fully address all aspects of the original prompt? Is anything missing?
* **Clarity & Coherence:** Is the language clear, concise, and easy to understand? Does it flow logically?
* **Tone & Style:** Does it match the desired tone and style (e.g., professional, engaging, concise)?
* **Engagement:** Is it captivating? Does it hold the reader's attention?
* **Redundancy/Verbosity:** Can any parts be condensed or removed without losing meaning?
4. **Propose Specific Improvements:** For each identified weakness, suggest concrete and actionable changes. Do not just state the problem; propose a solution.
5. **Generate Revised Content:** Based on your proposed improvements, rewrite the original content to incorporate all the necessary changes. Ensure the revised content is polished and ready for final use.
**Original Prompt/Requirements:** "Write a short, engaging social media post (max 150 characters) announcing a new eco-friendly product line: 'GreenTech Gadgets'."
**Initial Draft (Content to be corrected):** "We have new products. They are green and techy. Buy GreenTech Gadgets now!"
**Self-Correction Agent's Thought Process (Internal CoT Output - encouraged by the prompt):**
**Thought 1 (Understand Original Requirements):**
- Short, engaging social media post.
- Max 150 characters.
- Announce "GreenTech Gadgets" - a new eco-friendly product line.
**Thought 2 (Analyze Current Content):**
"We have new products. They are green and techy. Buy GreenTech Gadgets now!" (64 characters)
**Thought 3 (Identify Discrepancies/Weaknesses):**
- **Engaging:** Not very engaging. Sounds generic.
- **Eco-friendly:** Implied by "green," but not explicitly highlighted as a benefit.
- **Call to Action:** "Buy now!" is okay, but could be more compelling.
- **Conciseness:** It's short, but could use stronger verbs/phrasing.
- **Impact:** Lacks excitement for a new product launch.
**Thought 4 (Propose Specific Improvements):**
- Make it more dynamic and exciting.
- Emphasize "eco-friendly" and "innovation."
- Use stronger verbs and more active voice.
- Add a clear, engaging call to action.
- Ensure it stays under 150 characters.
**Thought 5 (Generate Revised Content):**
Original: "We have new products. They are green and techy. Buy GreenTech Gadgets now!"
Revised idea 1: "🌱 Discover GreenTech Gadgets! Our new eco-friendly line blends innovation with sustainability. Go green, go smart! Shop now! #EcoFriendly #GreenTech" (148 characters)
This revision directly addresses eco-friendliness, uses emojis for engagement, adds a stronger call to action, and includes relevant hashtags while staying within the character limit.
**Self-Correction Agent's Final Revised Content (Output to User):**
🌱 Discover GreenTech Gadgets! Our new eco-friendly line blends innovation with sustainability. Go green, go smart! Shop now! #EcoFriendly #GreenTech
从根本上讲,这项技术将质量控制措施直接集成到智能体的内容生成过程中,从而产生更加精细、精确和优越的结果,更有效地满足复杂多样的用户需求。
程序辅助语言模型(PALMs)将具有符号推理能力的LLM与符号推理能力相结合。这种集成使得LLM能够在问题解决过程中生成和执行代码,例如Python。PALMs将复杂的计算、逻辑运算和数据操作卸载到确定性编程环境中。这种方法利用了传统编程的优势,在LLM可能在准确性或一致性方面表现出局限性的任务中。面对符号挑战时,模型可以生成代码,执行它,并将结果转换为自然语言。这种混合方法结合了LLM的理解和生成能力与精确计算,使模型能够以更高的可靠性和准确性解决更广泛的复杂问题。这对于智能体来说很重要,因为它允许它们通过利用精确计算以及它们的理解和生成能力来执行更准确和可靠的操作。例如,在Google的ADK中使用外部工具生成代码就是一个例子。
from google.adk.tools import agent_tool
from google.adk.agents import Agent
from google.adk.tools import google_search
from google.adk.code_executors import BuiltInCodeExecutor
search_agent = Agent(
model='gemini-2.0-flash',
name='SearchAgent',
instruction="""You're a specialist in Google Search""",
tools=[google_search],
)
coding_agent = Agent(
model='gemini-2.0-flash',
name='CodeAgent',
instruction="""You're a specialist in Code Execution""",
code_executor=[BuiltInCodeExecutor],
)
root_agent = Agent(
name="RootAgent",
model="gemini-2.0-flash",
description="Root Agent",
tools=[
agent_tool.AgentTool(agent=search_agent),
agent_tool.AgentTool(agent=coding_agent),
],
)
可验证奖励强化学习(RLVR):虽然标准的思想链(CoT)提示在许多LLM中被广泛使用,但它是一种相对基础的理由推理方法。它生成一条单一的、预定的思维路线,而不适应问题的复杂性。为了克服这些限制,开发了一种新的专门化的“推理模型”类别。这些模型通过在提供答案之前分配可变数量的“思考”时间来运行,从而以不同的方式工作。这个“思考”过程产生了一个更广泛和动态的思想链,可以长达数千个标记。这种扩展的推理允许模型进行更复杂的操作,如自我纠正和回溯,模型会为更困难的问题投入更多的努力。使这些模型能够工作的关键创新是一种名为可验证奖励强化学习(RLVR)的训练策略。通过在具有已知正确答案的问题(如数学或代码)上训练模型,它通过试错学习生成有效的长篇推理。这使得模型能够在没有直接人类监督的情况下发展其解决问题的能力。最终,这些推理模型不仅提供答案,还生成一个“推理轨迹”,展示了高级技能,如规划、监控和评估。这种增强的推理和策略能力对于自主智能体的发展至关重要,这些智能体可以最小化人类干预,分解和解决复杂任务。
ReAct(推理与行动,见图3,其中KB代表知识库)是一种将思维链(CoT)提示与智能体通过工具与外部环境交互的能力相结合的范例。与生成模型产生最终答案不同,ReAct智能体会对采取哪些行动进行推理。这一推理阶段涉及一个类似于CoT的内部规划过程,其中智能体确定其下一步行动,考虑可用工具,并预测结果。随后,智能体通过执行工具或函数调用来进行行动,例如查询数据库、执行计算或与API交互。
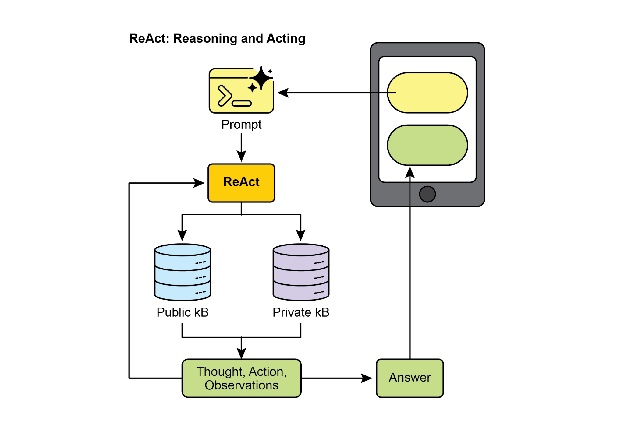
图3:推理与行动
ReAct以交错方式运行:智能体执行一个动作,观察结果,并将这一观察结果融入后续推理中。这种“思考、行动、观察、思考……”的迭代循环使智能体能够动态调整其计划,纠正错误,并实现需要与环境进行多次交互的目标。与线性CoT相比,这种更稳健、更灵活的问题解决方法,因为智能体能够对实时反馈做出响应。通过结合语言模型的理解和生成能力以及使用工具的能力,ReAct使智能体能够执行需要推理和实际执行的复杂任务。这种方法对于智能体至关重要,因为它不仅允许它们进行推理,还允许它们实际执行步骤并与动态环境交互。
CoD(辩论链)是微软提出的一种正式人工智能框架,其中多个不同的模型协同合作,进行辩论以解决问题,超越了单个AI的“思维链”。该系统运作类似于人工智能委员会会议,不同模型提出初步想法,相互批评对方的推理,并交换反驳论点。主要目标是利用集体智慧,提高准确性,减少偏见,并提升最终答案的整体质量。作为AI版本的同行评审,这种方法创建了一个透明且值得信赖的推理过程记录。最终,它代表着从单个提供答案的智能体向一个协同工作的智能体团队寻找更稳健和经过验证的解决方案的转变。
GoD(辩论图)是一个先进的智能体框架,它将讨论重新构想为一个动态的、非线性的网络,而不是简单的链条。在这个模型中,论点作为独立的节点,通过表示“支持”或“反驳”等关系的边连接起来,反映了真实辩论的多线程特性。这种结构允许新的探究线索动态分支、独立发展,甚至随着时间的推移而合并。结论不是在序列的末尾得出,而是在整个图中识别出最稳健且得到充分支持的论点簇。在此语境下,“得到充分支持”指的是牢固确立且可验证的知识。这可以包括被认为是基线事实的信息,这意味着它是内在正确的,并被广泛接受为事实。此外,它还包括通过搜索基座获得的事实证据,其中信息与外部来源和现实世界数据进行验证。最后,它还涉及多个模型在辩论中达成的共识,表明对所提供信息的同意度和信心度很高。这种全面的方法确保了讨论信息更加稳健和可靠的基础。这种方法为复杂、协作的AI推理提供了一个更加全面和现实的模型。
MASS(可选高级主题): 对多智能体系统设计的深入分析表明,其有效性取决于编程单个智能体所使用的提示质量以及决定它们交互的拓扑结构。设计这些系统的复杂性显著,因为它涉及一个庞大而复杂的搜索空间。为了应对这一挑战,开发了一个名为多智能体系统搜索(MASS)的新框架,以自动化和优化MAS的设计。
MASS采用了一种多阶段优化策略,通过交织提示和拓扑优化(见图4),系统地导航复杂的设计空间。
1. 块级提示优化:该过程从对单个智能体类型或“块”的提示进行局部优化开始,以确保每个组件在集成到更大系统之前都能有效执行其角色。这一初始步骤至关重要,因为它确保后续的拓扑优化建立在表现良好的智能体之上,而不是受到配置不当的智能体的累积影响。例如,在优化HotpotQA数据集时,"Debator"智能体的提示被巧妙地构建,指示其扮演“主要出版物的专家事实核查员”。其优化的任务是细致审查其他智能体提出的答案,将它们与提供的上下文段落进行交叉引用,并识别任何不一致或不支持的主张。这种在块级优化期间发现的特殊角色扮演提示,旨在使Debator智能体在进入更大工作流程之前就能高效地综合信息。
2. 工作流拓扑优化: 在局部优化之后,MASS通过从可定制的设计空间中选择和安排不同的智能体交互来优化工作流拓扑。为了使这一搜索过程高效,MASS采用了一种影响力加权方法。该方法通过测量相对于基线智能体的性能提升来计算每个拓扑的“增量影响力”,并使用这些分数来引导搜索,使其趋向于更有希望的组合。例如,在优化MBPP编码任务时,拓扑搜索发现特定的混合工作流最为有效。最佳发现的拓扑结构并非简单的结构,而是迭代细化过程与外部工具使用的组合。具体来说,它包括一个预测智能体,该智能体参与多轮反思,其代码由一个执行智能体验证,该执行智能体通过测试用例运行代码。这种发现的流程表明,对于编码任务,结合迭代自我校正与外部验证的结构比简单的MAS设计更优越。
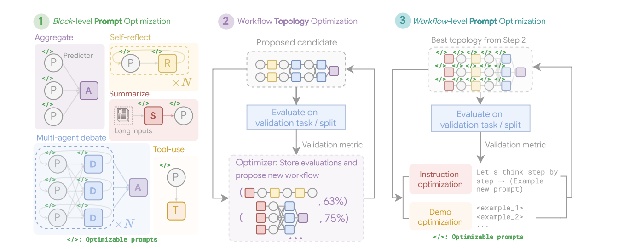
图4:(作者提供):多智能体系统搜索(MASS)框架是一个包含可优化提示(指令和演示)和可配置智能体构建块(聚合、反思、辩论、总结和工具使用)的搜索空间的三个阶段优化过程。第一阶段,块级提示优化,独立优化每个智能体模块的提示。第二阶段,工作流程拓扑优化,从影响加权的设计空间中采样有效的系统配置,整合优化后的提示。最终阶段,工作流程级提示优化,在确定第二阶段的最优工作流程后,对整个多智能体系统进行第二轮提示优化。
3. 工作流级提示优化: 最后的阶段涉及对整个系统提示的全球优化。在确定最佳拓扑结构后,提示作为单一、集成的实体进行微调,以确保它们针对编排进行了定制,并且智能体之间的依赖关系得到优化。例如,在找到DROP数据集的最佳拓扑结构后,最终优化阶段对“预测器”智能体的提示进行了细化。最终的优化提示非常详细,首先向智能体提供数据集本身的概述,指出其专注于“抽取式问答”和“数值信息”。然后,它包括正确问答行为的少量示例,并将核心指令框架为一个高风险场景:“你是一位高度专业的AI,负责为紧急新闻报道提取关键数值信息。现场直播依赖于你的准确性和速度”。这个多方面的提示,结合元知识、示例和角色扮演,专门针对最终工作流进行调优,以最大化准确性。
主要发现和原则:实验表明,通过MASS优化后的MAS在一系列任务中显著优于现有的手动设计系统和其它自动化设计方法。从这项研究中得出的有效MAS的关键设计原则有三点:
在组合智能体之前,请使用高质量的提示来优化单个智能体。 通过组合有影响力的拓扑结构来构建MAS(多智能体系统),而不是在无约束的搜索空间中进行探索。 通过最终的、工作流程级别的联合优化,对智能体之间的相互依赖关系进行建模和优化。
基于我们对关键推理技术的讨论,让我们首先考察一个核心性能原则:LLM的缩放推理定律。该定律指出,随着分配给模型的计算资源增加,其性能可预测地得到提升。我们可以在像深度研究这样的复杂系统中看到这一原则的实际应用,其中智能体利用这些资源通过将主题分解为子问题、利用网络搜索作为工具以及综合其发现来自主地研究一个主题。
深度研究。术语“深度研究”描述了一类AI智能体工具,旨在作为不知疲倦、有条理的研究助手。该领域的代表性平台包括Perplexity AI、谷歌的Gemini研究功能以及OpenAI在ChatGPT中的高级功能(见图5)。
 图5: Google使用Deep Research进行信息收集
图5: Google使用Deep Research进行信息收集
这些工具引入的一项基本转变是搜索过程本身的改变。传统的搜索提供即时链接,将综合工作留给你来完成。深度研究采用不同的模式。在这里,你将一个复杂的查询任务交给AI,并给它一个“时间预算”——通常几分钟。作为对这种耐心的回报,你将获得一份详细的报告。
在这段时间内,AI以智能体的方式代表您工作。它自主执行一系列复杂的步骤,这些步骤对于人类来说将非常耗时:
- 初始探索:它根据您的初始提示进行多次、有针对性的搜索。
- 推理与细化:它读取和分析第一波结果,综合研究结果,并批判性地识别差距、矛盾或需要更多细节的领域。
- 跟进询问:基于其内部推理,它进行新的、更细致的搜索来填补这些空白,并加深其理解。
- 最终合成:经过几轮迭代搜索和推理后,它将所有验证过的信息整合成一个单一、连贯且结构化的摘要。
这种系统化方法确保了全面且合乎逻辑的回应,显著提高了信息收集的效率和深度,从而促进了更具智能体的决策。
缩放推理法则
这一关键原则决定了大型语言模型(LLM)的性能与其在运行阶段(即推理阶段)分配的计算资源之间的关系。推理扩展定律与更熟悉的训练扩展定律不同,后者关注的是在模型创建过程中,随着数据量和计算能力的增加,模型质量如何提升。相反,该定律专门考察了LLM在积极生成输出或答案时发生的动态权衡。
该法律的一个基石是揭示,通过在推理时增加计算投入,通常可以使用相对较小的LLM获得更优异的结果。这并不一定意味着使用更强大的GPU,而是采用更复杂或资源密集型的推理策略。此类策略的一个典型例子是指导模型生成多个潜在答案——可能通过如多样化束搜索或自洽性方法等技术——然后使用选择机制来识别最优化输出。这种迭代优化或多候选生成过程需要更多的计算周期,但可以显著提升最终响应的质量。
这一原则为智能体系统的部署提供了关键框架,有助于做出信息丰富且经济合理的决策。它挑战了直观观念,即更大的模型总会带来更好的性能。该定律提出,在推理过程中,一个较小的模型如果被赋予更充裕的“思考预算”,有时甚至可以超越那些依赖更简单、计算量更少的生成过程的更大模型的性能。“思考预算”在这里指的是推理过程中额外的计算步骤或复杂的算法,使得较小的模型能够探索更广泛的可能范围,或在得出答案之前进行更严格的内部检查。
因此,缩放推理定律成为构建高效且经济的智能体系统的基础。它提供了一种方法,用于精心平衡多个相互关联的因素:
- 模型大小: 较小的模型在内存和存储方面需求较低。
- 响应延迟:虽然增加推理时间计算可能会增加延迟,但该法则有助于确定性能提升超过这一增加的点,或者如何战略性地应用计算以避免过度延迟。
- 运营成本: 部署和运行更大规模的模型通常会产生更高的持续运营成本,这主要是因为电力消耗和基础设施需求的增加。该文档展示了如何在无需不必要地增加这些成本的情况下优化性能。
通过理解和应用缩放推理定律,开发者和组织可以做出战略选择,从而为特定的智能体应用实现最佳性能,确保计算资源被分配到对LLM输出质量和效用产生最大影响的地方。这允许采取更加细腻且经济可行的AI部署方法,超越简单的“越大越好”的范式。
动手编码示例
DeepSearch代码由谷歌开源,可通过gemini-fullstack-langgraph-quickstart仓库获取(图6)。该仓库为开发者提供了一个模板,用于使用Gemini 2.5和LangGraph编排框架构建全栈AI智能体。这个开源栈简化了基于智能体的架构实验,并且可以与本地LLM(如Gemma)集成。它利用Docker和模块化项目脚手架进行快速原型设计。需要注意的是,这个版本作为结构良好的演示,并不旨在作为生产就绪的后端。
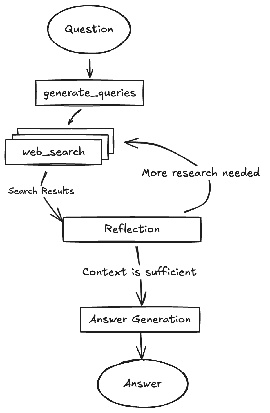
图6:(作者提供)DeepSearch多步反射示例
本项目提供了一个全栈应用程序,包括React前端和LangGraph后端,专为高级研究和对话式人工智能设计。LangGraph智能体使用Google Gemini模型动态生成搜索查询,并通过Google Search API整合网络研究。系统采用反思推理来识别知识差距,迭代优化搜索,并使用引文综合答案。前端和后端支持热重载。项目结构包括独立的 frontend/ 和 backend/ 目录。设置要求包括Node.js、npm、Python 3.8+ 以及Google Gemini API密钥。在将API密钥配置在后端的 .env 文件后,可以通过 (使用pip install .) 和前端 (npm install) 安装后端和前端的依赖项。可以使用make dev或单独运行开发服务器。后端智能体定义在 backend/src/agent/graph.py 中,生成初始搜索查询,进行网络研究,执行知识差距分析,迭代优化查询,并使用Gemini模型综合带有引文的答案。生产部署涉及后端服务器提供静态前端构建,并需要Redis进行实时输出流和Postgres数据库来管理数据。可以使用docker-compose up构建并运行Docker镜像,这还需要docker-compose.yml示例中的LangSmith API密钥。应用程序使用React与Vite、Tailwind CSS、Shadcn UI、LangGraph和Google Gemini。该项目采用Apache License 2.0许可。
# Create our Agent Graph
builder = StateGraph(OverallState, config_schema=Configuration)
# Define the nodes we will cycle between
builder.add_node("generate_query", generate_query)
builder.add_node("web_research", web_research)
builder.add_node("reflection", reflection)
builder.add_node("finalize_answer", finalize_answer)
# Set the entrypoint as `generate_query`
# This means that this node is the first one called
builder.add_edge(START, "generate_query")
# Add conditional edge to continue with search queries in a parallel branch
builder.add_conditional_edges(
"generate_query",
continue_to_web_research,
["web_research"]
)
# Reflect on the web research
builder.add_edge("web_research", "reflection")
# Evaluate the research
builder.add_conditional_edges(
"reflection",
evaluate_research,
["web_research", "finalize_answer"]
)
# Finalize the answer
builder.add_edge("finalize_answer", END)
graph = builder.compile(name="pro-search-agent")
图4:DeepSearch与LangGraph的示例(代码来自backend/src/agent/graph.py)
那么,智能体是如何想的?
总的来说,智能体的思考过程是一种结合推理和行动以解决问题的结构化方法。这种方法允许智能体明确规划其步骤,监控其进度,并与外部工具交互以收集信息。
智能体的“思考”核心由一个强大的LLM(大型语言模型)辅助。该LLM生成一系列思想,引导智能体进行后续行动。这个过程通常遵循一个思维-行动-观察的循环:
思考: 智能体首先生成一个文本形式的思考,用于分解问题、制定计划或分析当前情况。这种内部独白使得智能体的推理过程变得透明且可引导。 2. 动作: 基于思考,智能体从预定义的离散选项集中选择一个动作。例如,在问答场景中,动作空间可能包括在线搜索、从特定网页检索信息或提供最终答案。 3. 观察:智能体随后根据采取的行动从其环境中接收反馈。这可能包括网络搜索的结果或网页的内容。
这个循环会重复进行,每次观察都会影响下一个思考,直到智能体确定已经找到了最终解决方案并执行一个“完成”动作。
这种方法的成效依赖于底层LLM的高级推理和规划能力。为了引导智能体,ReAct框架通常采用少样本学习,即向LLM提供类似人类问题解决轨迹的示例。这些示例展示了如何有效地结合思考和行动来解决类似任务。
智能体的思维频率可以根据任务进行调整。对于像事实核查这样的知识密集型推理任务,思维通常与每个动作交织在一起,以确保信息收集和推理的逻辑流程。相比之下,对于需要许多动作的决策任务,例如在模拟环境中导航,思维可能被更加节约地使用,允许智能体决定何时进行思考。
概览
内容:复杂问题解决通常需要不止一个直接答案,这对人工智能来说是一个重大挑战。核心问题在于使智能体能够处理需要逻辑推理、分解和战略规划的多步任务。如果没有结构化的方法,智能体可能无法处理复杂性,导致结论不准确或不完整。这些高级推理方法旨在使智能体的内部“思考”过程变得明确,使其能够系统地解决挑战。
原因: 标准化解决方案是一套推理技术,为智能体的问题解决过程提供了一个结构化的框架。例如,思维链(CoT)和思维树(ToT)等方法论指导大型语言模型分解问题并探索多种解决方案路径。自我纠正允许对答案进行迭代优化,确保更高的准确性。像ReAct这样的智能体框架将推理与行动相结合,使智能体能够与外部工具和环境交互以获取信息并调整其计划。这种显式推理、探索、优化和工具使用的组合,创造了更稳健、透明和强大的AI系统。
经验法则: 当一个问题过于复杂,无法通过单次回答解决,需要分解、多步骤逻辑、与外部数据源或工具交互,或战略规划与适应时,请使用这些推理技术。它们非常适合那些展示“解题过程”或思维过程与最终答案同样重要的任务。
视觉摘要
图7:推理设计模式
关键要点
通过使推理过程明确化,智能体可以制定透明、多步骤的计划,这是自主行动和用户信任的基础能力。 ReAct框架为智能体提供了其核心操作循环,使它们能够超越单纯的推理,与外部工具交互,以在环境中动态行动和适应。 缩放推理定律表明,智能体的性能不仅与其底层模型大小有关,还与其分配的“思考时间”有关,这允许进行更加谨慎且质量更高的自主行动。 思维链(CoT)充当智能体的内心独白,提供了一种结构化的方式,通过将复杂目标分解为一系列可管理的行动来制定计划。 思维树和自我纠错能力赋予智能体深思熟虑的能力,使他们能够评估多种策略,从错误中回溯,并在执行前改进自己的计划。 协作框架如辩论链(CoD)标志着从单个智能体向多智能体系统的转变,其中智能体团队可以共同推理以解决更复杂的问题并减少个体偏见。 像深度研究(Deep Research)这样的应用展示了这些技术如何汇聚成能够代表用户完全自主执行复杂、长时间任务的智能体,例如进行深入调查。 为了构建有效的智能体团队,MASS 等框架自动化了单个智能体的指令优化以及它们之间的交互,确保整个多智能体系统能够以最佳性能运行。 通过整合这些推理技术,我们构建的智能体不仅实现了自动化,更是真正实现了自主性,能够被信赖去规划、行动和解决复杂问题,而无需直接监督。
结论
现代人工智能正在从被动工具演变为自主智能体,能够通过结构化推理来应对复杂目标。这种智能体行为始于内部独白,由诸如思维链(CoT)等技术驱动,使智能体在行动前能够制定出连贯的计划。真正的自主性需要深思熟虑,智能体通过自我纠正和思维树(ToT)来实现这一点,使它们能够评估多种策略并独立改进自己的工作。向完全自主系统的关键飞跃来自于ReAct框架,它使智能体能够通过使用外部工具超越思考,开始行动。这建立了核心的智能体循环——思考、行动和观察,使智能体能够根据环境反馈动态调整其策略。
智能体的深度思考能力得益于扩展推理定律,其中更多的计算“思考时间”直接转化为更稳健的自主行动。下一个前沿是多智能体系统,其中像辩论链(CoD)这样的框架创建了协作的智能体社会,这些智能体共同推理以实现共同目标。这并非理论上的设想;像深度研究这样的智能体应用已经展示了智能体如何代表用户执行复杂的多步骤调查。总体目标是构建可靠且透明的自主智能体,人们可以信任它们独立管理和解决复杂问题。最终,通过结合显式推理和行动能力,这些方法正在完成将人工智能转变为真正具有智能体能力的解决问题的转变。
参考文献
相关研究包括:
- 《大型语言模型中的思维链提示引发推理》——韦等(2022年)
- "思维树:使用大型语言模型进行深思熟虑的问题解决" —— Yao等人(2023年)
- 高等等著,《程序辅助语言模型》(2023年)
- "ReAct:在语言模型中协同推理与行动" —— Yao等人(2023年)
- 推理缩放定律:针对LLM问题解决的计算最优推理的实证分析,2024
- 多智能体设计:通过更好的提示和拓扑优化智能体